Zero-Shot Everything Sketch-Based Image Retrieval, and in Explainable Style
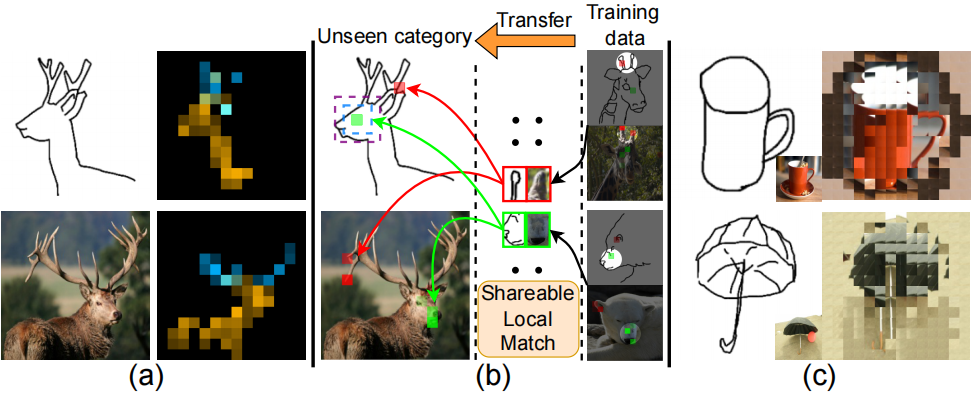
This paper studies the problem of zero-short sketch-based image retrieval (ZS-SBIR), however with two significant differentiators to prior art (i) we tackle all variants (inter-category, intra-category, and cross datasets) of ZS-SBIR with just one network (``everything''), and (ii) we would really like to understand how this sketch-photo matching operates (``explainable''). Our key innovation lies with the realization that such a cross-modal matching problem could be reduced to comparisons of groups of key local patches -- akin to the seasoned ``bag-of-words'' paradigm. Just with this change, we are able to achieve both of the aforementioned goals, with the added benefit of no longer requiring external semantic knowledge. Technically, ours is a transformer-based cross-modal network, with three novel components (i) a self-attention module with a learnable tokenizer to produce visual tokens that correspond to the most informative local regions, (ii) a cross-attention module to compute local correspondences between the visual tokens across two modalities, and finally (iii) a kernel-based relation network to assemble local putative matches and produce an overall similarity metric for a sketch-photo pair. Experiments show ours indeed delivers superior performances across all ZS-SBIR settings. The all important explainable goal is elegantly achieved by visualizing cross-modal token correspondences, and for the first time, via sketch to photo synthesis by universal replacement of all matched photo patches. Code and model are available at \url{https://github.com/buptLinfy/ZSE-SBIR}.
PDF Abstract CVPR 2023 PDF CVPR 2023 Abstract


 ImageNet
ImageNet
 Sketch
Sketch
