Zero-Shot Information Extraction as a Unified Text-to-Triple Translation
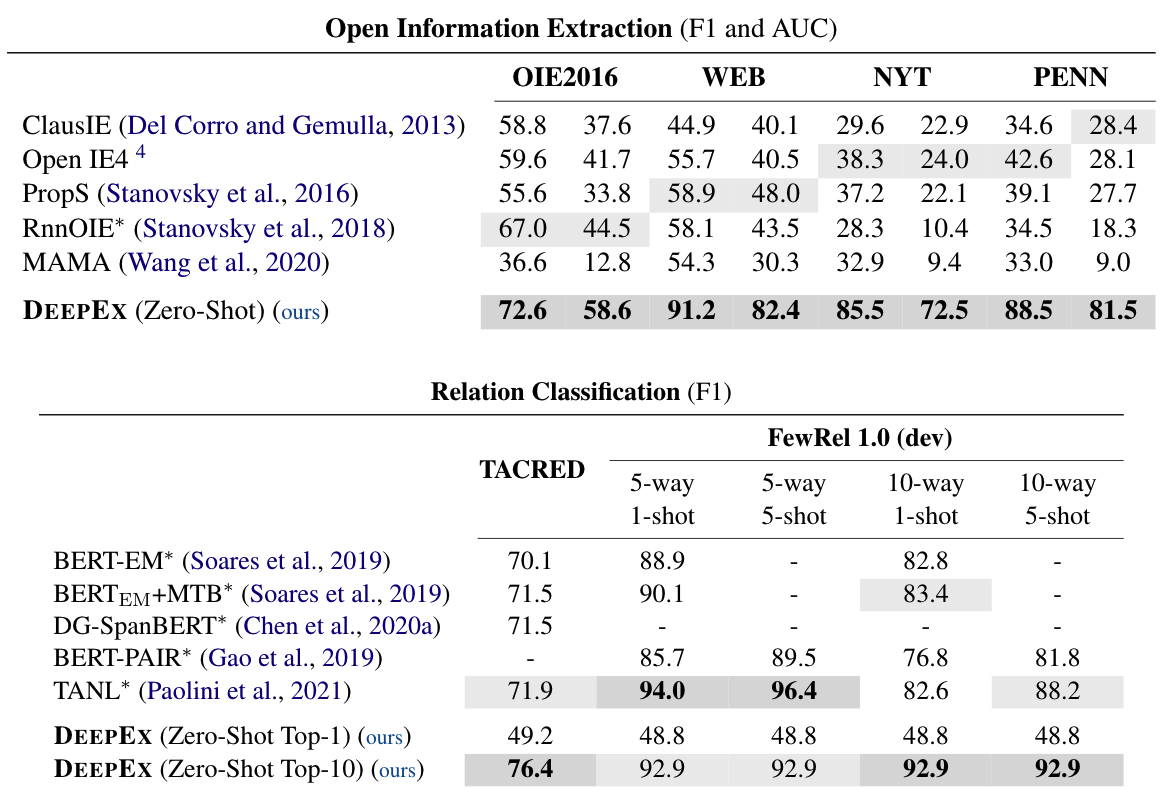
We cast a suite of information extraction tasks into a text-to-triple translation framework. Instead of solving each task relying on task-specific datasets and models, we formalize the task as a translation between task-specific input text and output triples. By taking the task-specific input, we enable a task-agnostic translation by leveraging the latent knowledge that a pre-trained language model has about the task. We further demonstrate that a simple pre-training task of predicting which relational information corresponds to which input text is an effective way to produce task-specific outputs. This enables the zero-shot transfer of our framework to downstream tasks. We study the zero-shot performance of this framework on open information extraction (OIE2016, NYT, WEB, PENN), relation classification (FewRel and TACRED), and factual probe (Google-RE and T-REx). The model transfers non-trivially to most tasks and is often competitive with a fully supervised method without the need for any task-specific training. For instance, we significantly outperform the F1 score of the supervised open information extraction without needing to use its training set.
PDF Abstract EMNLP 2021 PDF EMNLP 2021 AbstractCode



 Penn Treebank
Penn Treebank
 New York Times Annotated Corpus
New York Times Annotated Corpus
 TACRED
TACRED
 FewRel
FewRel
Results from the Paper
 Ranked #1 on
Open Information Extraction
on OIE2016
(using extra training data)
Ranked #1 on
Open Information Extraction
on OIE2016
(using extra training data)
