Zero-Shot Multi-Speaker Text-To-Speech with State-of-the-art Neural Speaker Embeddings
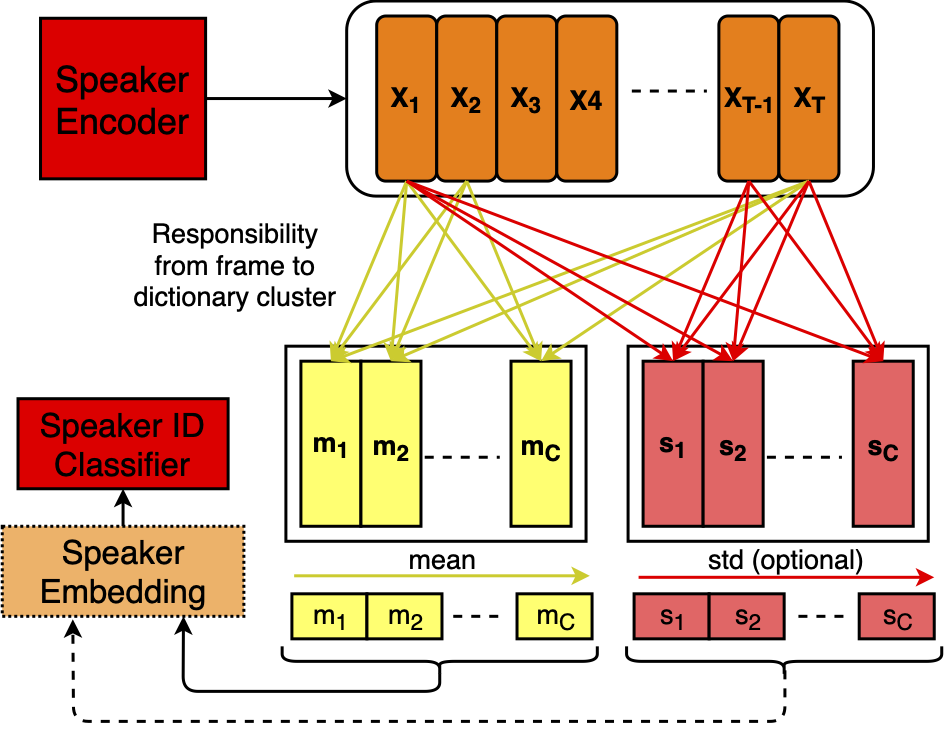
While speaker adaptation for end-to-end speech synthesis using speaker embeddings can produce good speaker similarity for speakers seen during training, there remains a gap for zero-shot adaptation to unseen speakers. We investigate multi-speaker modeling for end-to-end text-to-speech synthesis and study the effects of different types of state-of-the-art neural speaker embeddings on speaker similarity for unseen speakers. Learnable dictionary encoding-based speaker embeddings with angular softmax loss can improve equal error rates over x-vectors in a speaker verification task; these embeddings also improve speaker similarity and naturalness for unseen speakers when used for zero-shot adaptation to new speakers in end-to-end speech synthesis.
PDF Abstract

 VoxCeleb1
VoxCeleb1
