Zoom To Learn, Learn To Zoom
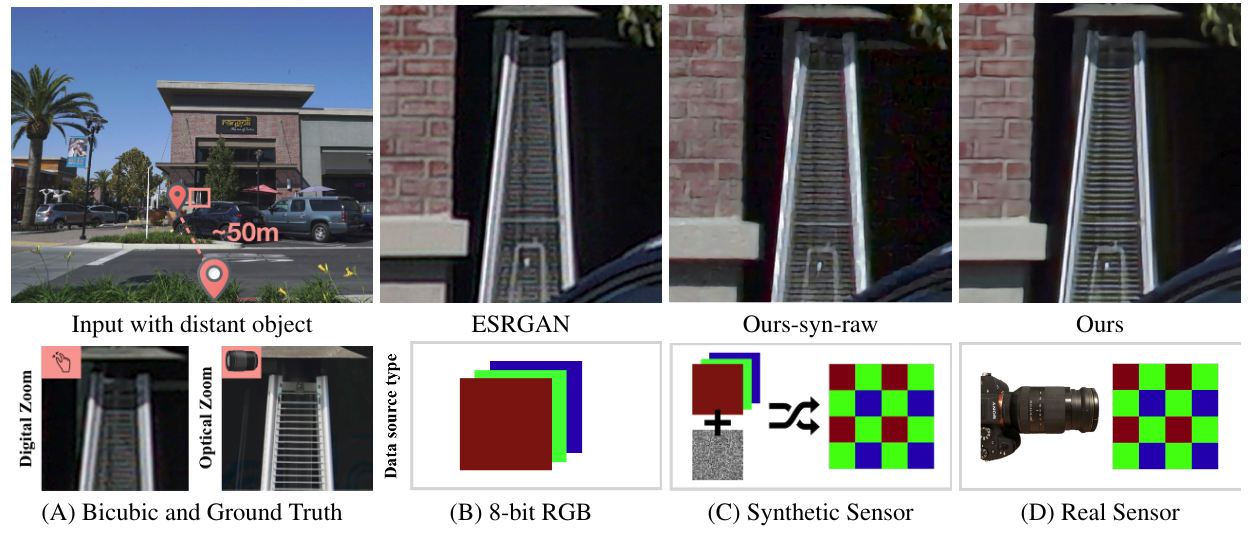
This paper shows that when applying machine learning to digital zoom for photography, it is beneficial to use real, RAW sensor data for training. Existing learning-based super-resolution methods do not use real sensor data, instead operating on RGB images. In practice, these approaches result in loss of detail and accuracy in their digitally zoomed output when zooming in on distant image regions. We also show that synthesizing sensor data by resampling high-resolution RGB images is an oversimplified approximation of real sensor data and noise, resulting in worse image quality. The key barrier to using real sensor data for training is that ground truth high-resolution imagery is missing. We show how to obtain the ground-truth data with optically zoomed images and contribute a dataset, SR-RAW, for real-world computational zoom. We use SR-RAW to train a deep network with a novel contextual bilateral loss (CoBi) that delivers critical robustness to mild misalignment in input-output image pairs. The trained network achieves state-of-the-art performance in 4X and 8X computational zoom.
PDF AbstractCode

Tasks

Datasets
Introduced in the Paper:
 SR-RAW
SR-RAW
