Search Results for author:
Found 75 papers, 40 papers with code
Segment Anything in High Quality
HQ-SAM is only trained on the introduced detaset of 44k masks, which takes only 4 hours on 8 GPUs.
 Ranked #1 on
Zero-Shot Instance Segmentation
on LVIS v1.0 val
Ranked #1 on
Zero-Shot Instance Segmentation
on LVIS v1.0 val

Segment Anything Meets Point Tracking
The Segment Anything Model (SAM) has established itself as a powerful zero-shot image segmentation model, enabled by efficient point-centric annotation and prompt-based models.
CascadePSP: Toward Class-Agnostic and Very High-Resolution Segmentation via Global and Local Refinement
In this paper, we propose a novel approach to address the high-resolution segmentation problem without using any high-resolution training data.
 Ranked #1 on
Semantic Segmentation
on BIG
(using extra training data)
Ranked #1 on
Semantic Segmentation
on BIG
(using extra training data)
Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation
This paper presents a simple yet effective approach to modeling space-time correspondences in the context of video object segmentation.
 Ranked #7 on
Video Object Segmentation
on YouTube-VOS 2019
Ranked #7 on
Video Object Segmentation
on YouTube-VOS 2019
 Semantic Segmentation
Semantic Segmentation
 Semi-Supervised Video Object Segmentation
+1
Semi-Supervised Video Object Segmentation
+1
Mask Transfiner for High-Quality Instance Segmentation
Instead of operating on regular dense tensors, our Mask Transfiner decomposes and represents the image regions as a quadtree.
 Ranked #1 on
Instance Segmentation
on BDD100K val
Ranked #1 on
Instance Segmentation
on BDD100K val

Deep Occlusion-Aware Instance Segmentation with Overlapping BiLayers
Segmenting highly-overlapping objects is challenging, because typically no distinction is made between real object contours and occlusion boundaries.
 Ranked #1 on
Instance Segmentation
on KINS
Ranked #1 on
Instance Segmentation
on KINS
Occlusion-Aware Instance Segmentation via BiLayer Network Architectures
Unlike previous instance segmentation methods, we model image formation as a composition of two overlapping layers, and propose Bilayer Convolutional Network (BCNet), where the top layer detects occluding objects (occluders) and the bottom layer infers partially occluded instances (occludees).
Modular Interactive Video Object Segmentation: Interaction-to-Mask, Propagation and Difference-Aware Fusion
We present Modular interactive VOS (MiVOS) framework which decouples interaction-to-mask and mask propagation, allowing for higher generalizability and better performance.
 Ranked #1 on
Interactive Video Object Segmentation
on DAVIS 2017
(using extra training data)
Ranked #1 on
Interactive Video Object Segmentation
on DAVIS 2017
(using extra training data)
 Interactive Video Object Segmentation
Semantic Segmentation
+2
Interactive Video Object Segmentation
Semantic Segmentation
+2
Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures
We alternate the pruning and retraining to further reduce zero activations in a network.
Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector
To train our network, we contribute a new dataset that contains 1000 categories of various objects with high-quality annotations.
 Ranked #21 on
Few-Shot Object Detection
on MS-COCO (10-shot)
Ranked #21 on
Few-Shot Object Detection
on MS-COCO (10-shot)

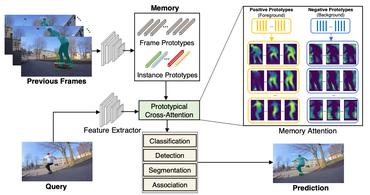
Prototypical Cross-Attention Networks for Multiple Object Tracking and Segmentation
We propose Prototypical Cross-Attention Network (PCAN), capable of leveraging rich spatio-temporal information for online multiple object tracking and segmentation.
 Ranked #1 on
Video Instance Segmentation
on BDD100K val
Ranked #1 on
Video Instance Segmentation
on BDD100K val
 Multi-Object Tracking and Segmentation
Multi-Object Tracking and Segmentation
 Multiple Object Track and Segmentation
+3
Multiple Object Track and Segmentation
+3
Mask-Free Video Instance Segmentation
A consistency loss is then enforced on the found matches.


Commonality-Parsing Network across Shape and Appearance for Partially Supervised Instance Segmentation
We propose to learn the underlying class-agnostic commonalities that can be generalized from mask-annotated categories to novel categories.
 Ranked #79 on
Instance Segmentation
on COCO test-dev
Ranked #79 on
Instance Segmentation
on COCO test-dev
Few-Shot Video Object Detection
We introduce Few-Shot Video Object Detection (FSVOD) with three contributions to real-world visual learning challenge in our highly diverse and dynamic world: 1) a large-scale video dataset FSVOD-500 comprising of 500 classes with class-balanced videos in each category for few-shot learning; 2) a novel Tube Proposal Network (TPN) to generate high-quality video tube proposals for aggregating feature representation for the target video object which can be highly dynamic; 3) a strategically improved Temporal Matching Network (TMN+) for matching representative query tube features with better discriminative ability thus achieving higher diversity.
Cascaded deep monocular 3D human pose estimation with evolutionary training data
End-to-end deep representation learning has achieved remarkable accuracy for monocular 3D human pose estimation, yet these models may fail for unseen poses with limited and fixed training data.
 Ranked #13 on
Weakly-supervised 3D Human Pose Estimation
on Human3.6M
Ranked #13 on
Weakly-supervised 3D Human Pose Estimation
on Human3.6M

FSS-1000: A 1000-Class Dataset for Few-Shot Segmentation
In this paper, we are interested in few-shot object segmentation where the number of annotated training examples are limited to 5 only.
 Ranked #20 on
Few-Shot Semantic Segmentation
on FSS-1000 (5-shot)
Ranked #20 on
Few-Shot Semantic Segmentation
on FSS-1000 (5-shot)

Semantic Image Matting
Specifically, we consider and learn 20 classes of matting patterns, and propose to extend the conventional trimap to semantic trimap.

NeRF-RPN: A general framework for object detection in NeRFs
This paper presents the first significant object detection framework, NeRF-RPN, which directly operates on NeRF.

Deep High Dynamic Range Imaging with Large Foreground Motions
In state-of-the-art deep HDR imaging, input images are first aligned using optical flows before merging, which are still error-prone due to occlusion and large motions.
LADN: Local Adversarial Disentangling Network for Facial Makeup and De-Makeup
Central to our method are multiple and overlapping local adversarial discriminators in a content-style disentangling network for achieving local detail transfer between facial images, with the use of asymmetric loss functions for dramatic makeup styles with high-frequency details.

GCoNet+: A Stronger Group Collaborative Co-Salient Object Detector
In this paper, we present a novel end-to-end group collaborative learning network, termed GCoNet+, which can effectively and efficiently (250 fps) identify co-salient objects in natural scenes.
 Ranked #1 on
Co-Salient Object Detection
on CoCA
Ranked #1 on
Co-Salient Object Detection
on CoCA

GSNet: Joint Vehicle Pose and Shape Reconstruction with Geometrical and Scene-aware Supervision
GSNet utilizes a unique four-way feature extraction and fusion scheme and directly regresses 6DoF poses and shapes in a single forward pass.
 Ranked #1 on
Autonomous Driving
on ApolloCar3D
Ranked #1 on
Autonomous Driving
on ApolloCar3D


Deep Video Matting via Spatio-Temporal Alignment and Aggregation
Despite the significant progress made by deep learning in natural image matting, there has been so far no representative work on deep learning for video matting due to the inherent technical challenges in reasoning temporal domain and lack of large-scale video matting datasets.

Human Instance Matting via Mutual Guidance and Multi-Instance Refinement
A new instance matting metric called instance matting quality (IMQ) is proposed, which addresses the absence of a unified and fair means of evaluation emphasizing both instance recognition and matting quality.
Cascade-DETR: Delving into High-Quality Universal Object Detection
While dominating on the COCO benchmark, recent Transformer-based detection methods are not competitive in diverse domains.
Self-Support Few-Shot Semantic Segmentation
Motivated by the simple Gestalt principle that pixels belonging to the same object are more similar than those to different objects of same class, we propose a novel self-support matching strategy to alleviate this problem, which uses query prototypes to match query features, where the query prototypes are collected from high-confidence query predictions.
 Ranked #12 on
Few-Shot Semantic Segmentation
on PASCAL-5i (5-Shot)
Ranked #12 on
Few-Shot Semantic Segmentation
on PASCAL-5i (5-Shot)
Image Generation from Sketch Constraint Using Contextual GAN
We train a generated adversarial network, i. e, contextual GAN to learn the joint distribution of sketch and the corresponding image by using joint images.

Stable Segment Anything Model
Thus, our solution, termed Stable-SAM, offers several advantages: 1) improved SAM's segmentation stability across a wide range of prompt qualities, while 2) retaining SAM's powerful promptable segmentation efficiency and generality, with 3) minimal learnable parameters (0. 08 M) and fast adaptation (by 1 training epoch).
FaceDNeRF: Semantics-Driven Face Reconstruction, Prompt Editing and Relighting with Diffusion Models
The ability to create high-quality 3D faces from a single image has become increasingly important with wide applications in video conferencing, AR/VR, and advanced video editing in movie industries.

Instance Neural Radiance Field
This paper presents one of the first learning-based NeRF 3D instance segmentation pipelines, dubbed as {\bf \inerflong}, or \inerf.


Ultrahigh Resolution Image/Video Matting With Spatio-Temporal Sparsity
Instead, our method resorts to spatial and temporal sparsity for solving general UHR matting.

DragVideo: Interactive Drag-style Video Editing
The main issues are: 1) how to perform direct and accurate user control in editing; 2) how to execute editings like changing shape, expression, and layout without unsightly distortion and artifacts to the edited content; and 3) how to maintain spatio-temporal consistency of video after editing.

Video Mask Transfiner for High-Quality Video Instance Segmentation
While Video Instance Segmentation (VIS) has seen rapid progress, current approaches struggle to predict high-quality masks with accurate boundary details.
 Ranked #1 on
Video Instance Segmentation
on HQ-YTVIS
Ranked #1 on
Video Instance Segmentation
on HQ-YTVIS
One-Shot Object Detection without Fine-Tuning
Deep learning has revolutionized object detection thanks to large-scale datasets, but their object categories are still arguably very limited.

FED-NeRF: Achieve High 3D Consistency and Temporal Coherence for Face Video Editing on Dynamic NeRF
However, achieving simultaneously multi-view consistency and temporal coherence while editing video sequences remains a formidable challenge.
FLNeRF: 3D Facial Landmarks Estimation in Neural Radiance Fields
This paper presents the first significant work on directly predicting 3D face landmarks on neural radiance fields (NeRFs).
Semi-Supervised Few-Shot Atomic Action Recognition
Despite excellent progress has been made, the performance on action recognition still heavily relies on specific datasets, which are difficult to extend new action classes due to labor-intensive labeling.
Distill Gold from Massive Ores: Efficient Dataset Distillation via Critical Samples Selection
Our method consistently enhances the distillation algorithms, even on much larger-scale and more heterogeneous datasets, e. g. ImageNet-1K and Kinetics-400.
Deceptive-Human: Prompt-to-NeRF 3D Human Generation with 3D-Consistent Synthetic Images
This paper presents Deceptive-Human, a novel Prompt-to-NeRF framework capitalizing state-of-the-art control diffusion models (e. g., ControlNet) to generate a high-quality controllable 3D human NeRF.
Interactiveness Field in Human-Object Interactions
Human-Object Interaction (HOI) detection plays a core role in activity understanding.
Annotation-Free and One-Shot Learning for Instance Segmentation of Homogeneous Object Clusters
We propose a novel approach for instance segmen- tation given an image of homogeneous object clus- ter (HOC).

Deep Video Generation, Prediction and Completion of Human Action Sequences
In the second stage, a skeleton-to-image network is trained, which is used to generate a human action video given the complete human pose sequence generated in the first stage.
 Ranked #5 on
Human action generation
on NTU RGB+D 2D
Ranked #5 on
Human action generation
on NTU RGB+D 2D

MAVOT: Memory-Augmented Video Object Tracking
We introduce a one-shot learning approach for video object tracking.
Attribute-Guided Face Generation Using Conditional CycleGAN
We are interested in attribute-guided face generation: given a low-res face input image, an attribute vector that can be extracted from a high-res image (attribute image), our new method generates a high-res face image for the low-res input that satisfies the given attributes.

Beyond Holistic Object Recognition: Enriching Image Understanding with Part States
Important high-level vision tasks such as human-object interaction, image captioning and robotic manipulation require rich semantic descriptions of objects at part level.

A Closed-Form Solution to Tensor Voting: Theory and Applications
We prove a closed-form solution to tensor voting (CFTV): given a point set in any dimensions, our closed-form solution provides an exact, continuous and efficient algorithm for computing a structure-aware tensor that simultaneously achieves salient structure detection and outlier attenuation.
1-HKUST: Object Detection in ILSVRC 2014
We participated in the object detection track of ILSVRC 2014 and received the fourth place among the 38 teams.


Shadow Removal from Single RGB-D Images
We present the first automatic method to remove shadows from single RGB-D images.
Two-Class Weather Classification
Given a single outdoor image, this paper proposes a collaborative learning approach for labeling it as either sunny or cloudy.


Complexity-Adaptive Distance Metric for Object Proposals Generation
Distance metric plays a key role in grouping superpixels to produce object proposals for object detection.
Contour Box: Rejecting Object Proposals Without Explicit Closed Contours
Closed contour is an important objectness indicator.
Square Localization for Efficient and Accurate Object Detection
In the testing phase, sliding CNN models are applied which produces a set of response maps that can be effectively filtered by the learned co-presence prior to output the final bounding boxes for localizing an object.
Online Video Object Detection Using Association LSTM
Video object detection is a fundamental tool for many applications.
StableNet: Semi-Online, Multi-Scale Deep Video Stabilization
Video stabilization algorithms are of greater importance nowadays with the prevalence of hand-held devices which unavoidably produce videos with undesirable shaky motions.
DAWN: Dual Augmented Memory Network for Unsupervised Video Object Tracking
Our Dual Augmented Memory Network (DAWN) is unique in remembering both target and background, and using an improved attention LSTM memory to guide the focus on memorized features.
Template-Instance Loss for Offline Handwritten Chinese Character Recognition
The long-standing challenges for offline handwritten Chinese character recognition (HCCR) are twofold: Chinese characters can be very diverse and complicated while similarly looking, and cursive handwriting (due to increased writing speed and infrequent pen lifting) makes strokes and even characters connected together in a flowing manner.
Fast Video Object Segmentation With Temporal Aggregation Network and Dynamic Template Matching
Significant progress has been made in Video Object Segmentation (VOS), the video object tracking task in its finest level.
![]() Ranked #71 on
Semi-Supervised Video Object Segmentation
on DAVIS 2016
Ranked #71 on
Semi-Supervised Video Object Segmentation
on DAVIS 2016
Pose-Guided High-Resolution Appearance Transfer via Progressive Training
We propose a novel pose-guided appearance transfer network for transferring a given reference appearance to a target pose in unprecedented image resolution (1024 * 1024), given respectively an image of the reference and target person.
HAA500: Human-Centric Atomic Action Dataset with Curated Videos
We contribute HAA500, a manually annotated human-centric atomic action dataset for action recognition on 500 classes with over 591K labeled frames.
 Ranked #1 on
Action Recognition
on HAA500
Ranked #1 on
Action Recognition
on HAA500

Occlusion-Aware Video Object Inpainting
To facilitate this new research, we construct the first large-scale video object inpainting benchmark YouTube-VOI to provide realistic occlusion scenarios with both occluded and visible object masks available.
HAA4D: Few-Shot Human Atomic Action Recognition via 3D Spatio-Temporal Skeletal Alignment
All training and testing 3D skeletons in HAA4D are globally aligned, using a deep alignment model to the same global space, making each skeleton face the negative z-direction.
Unsupervised Multi-View Object Segmentation Using Radiance Field Propagation
The core of our method is a novel propagation strategy for individual objects' radiance fields with a bidirectional photometric loss, enabling an unsupervised partitioning of a scene into salient or meaningful regions corresponding to different object instances.
Normalization Perturbation: A Simple Domain Generalization Method for Real-World Domain Shifts
Thus, we propose to perturb the channel statistics of source domain features to synthesize various latent styles, so that the trained deep model can perceive diverse potential domains and generalizes well even without observations of target domain data in training.

H-VFI: Hierarchical Frame Interpolation for Videos with Large Motions
The learnt deformable kernel is then utilized in convolving the input frames for predicting the interpolated frame.
ONeRF: Unsupervised 3D Object Segmentation from Multiple Views
We present ONeRF, a method that automatically segments and reconstructs object instances in 3D from multi-view RGB images without any additional manual annotations.
Clean-NeRF: Reformulating NeRF to account for View-Dependent Observations
This paper analyzes the NeRF's struggles in such settings and proposes Clean-NeRF for accurate 3D reconstruction and novel view rendering in complex scenes.

Registering Neural Radiance Fields as 3D Density Images
No significant work has been done to directly merge two partially overlapping scenes using NeRF representations.

Deceptive-NeRF: Enhancing NeRF Reconstruction using Pseudo-Observations from Diffusion Models
We introduce Deceptive-NeRF, a novel methodology for few-shot NeRF reconstruction, which leverages diffusion models to synthesize plausible pseudo-observations to improve the reconstruction.
UniBoost: Unsupervised Unimodal Pre-training for Boosting Zero-shot Vision-Language Tasks
Our thorough studies validate that models pre-trained as such can learn rich representations of both modalities, improving their ability to understand how images and text relate to each other.
EgoPCA: A New Framework for Egocentric Hand-Object Interaction Understanding
With the surge in attention to Egocentric Hand-Object Interaction (Ego-HOI), large-scale datasets such as Ego4D and EPIC-KITCHENS have been proposed.
C3Net: Compound Conditioned ControlNet for Multimodal Content Generation
Specifically, C3Net first aligns the conditions from multi-modalities to the same semantic latent space using modality-specific encoders based on contrastive training.
SANeRF-HQ: Segment Anything for NeRF in High Quality
Recently, the Segment Anything Model (SAM) has showcased remarkable capabilities of zero-shot segmentation, while NeRF (Neural Radiance Fields) has gained popularity as a method for various 3D problems beyond novel view synthesis.

Prompt2NeRF-PIL: Fast NeRF Generation via Pretrained Implicit Latent
This paper explores promptable NeRF generation (e. g., text prompt or single image prompt) for direct conditioning and fast generation of NeRF parameters for the underlying 3D scenes, thus undoing complex intermediate steps while providing full 3D generation with conditional control.
Inpaint4DNeRF: Promptable Spatio-Temporal NeRF Inpainting with Generative Diffusion Models
Second and the remaining problem is thus 3D multiview consistency among all completed images, now guided by the seed images and their 3D proxies.
