Search Results for author:
Found 190 papers, 91 papers with code
CLIP-GS: CLIP-Informed Gaussian Splatting for Real-time and View-consistent 3D Semantic Understanding
Additionally, to address the semantic ambiguity, caused by utilizing view-inconsistent 2D CLIP semantics to supervise Gaussians, we introduce a 3D Coherent Self-training (3DCS) strategy, resorting to the multi-view consistency originated from the 3D model.
TryOn-Adapter: Efficient Fine-Grained Clothing Identity Adaptation for High-Fidelity Virtual Try-On
However, the clothing identity uncontrollability and training inefficiency of existing diffusion-based methods, which struggle to maintain the identity even with full parameter training, are significant limitations that hinder the widespread applications.
DreamSalon: A Staged Diffusion Framework for Preserving Identity-Context in Editable Face Generation
While large-scale pre-trained text-to-image models can synthesize diverse and high-quality human-centered images, novel challenges arise with a nuanced task of "identity fine editing": precisely modifying specific features of a subject while maintaining its inherent identity and context.


Decoupled Pseudo-labeling for Semi-Supervised Monocular 3D Object Detection
Additionally, we present a DepthGradient Projection (DGP) module to mitigate optimization conflicts caused by noisy depth supervision of pseudo-labels, effectively decoupling the depth gradient and removing conflicting gradients.
TexRO: Generating Delicate Textures of 3D Models by Recursive Optimization
We propose an optimal viewpoint selection strategy, that finds the most miniature set of viewpoints covering all the faces of a mesh.
Gradient-based Sampling for Class Imbalanced Semi-supervised Object Detection
To tackle the confirmation bias from incorrect pseudo labels of minority classes, the class-rebalancing sampling module resamples unlabeled data following the guidance of the gradient-based reweighting module.

GGRt: Towards Pose-free Generalizable 3D Gaussian Splatting in Real-time
Specifically, we design a novel joint learning framework that consists of an Iterative Pose Optimization Network (IPO-Net) and a Generalizable 3D-Gaussians (G-3DG) model.

Learning to Rematch Mismatched Pairs for Robust Cross-Modal Retrieval
To achieve this, we propose L2RM, a general framework based on Optimal Transport (OT) that learns to rematch mismatched pairs.
VRP-SAM: SAM with Visual Reference Prompt
In this paper, we propose a novel Visual Reference Prompt (VRP) encoder that empowers the Segment Anything Model (SAM) to utilize annotated reference images as prompts for segmentation, creating the VRP-SAM model.

GVA: Reconstructing Vivid 3D Gaussian Avatars from Monocular Videos
In this paper, we present a novel method that facilitates the creation of vivid 3D Gaussian avatars from monocular video inputs (GVA).

Collaborative Position Reasoning Network for Referring Image Segmentation
Holi integrates features of the two modalities by a cross-modal attention mechanism, which suppresses the irrelevant redundancy under the guide of positioning information from RoCo.
M2-CLIP: A Multimodal, Multi-task Adapting Framework for Video Action Recognition
In this paper, we introduce a novel Multimodal, Multi-task CLIP adapting framework named \name to address these challenges, preserving both high supervised performance and robust transferability.


MS-DETR: Efficient DETR Training with Mixed Supervision
The traditional training procedure using one-to-one supervision in the original DETR lacks direct supervision for the object detection candidates.
Forgery-aware Adaptive Transformer for Generalizable Synthetic Image Detection
In this paper, we study the problem of generalizable synthetic image detection, aiming to detect forgery images from diverse generative methods, e. g., GANs and diffusion models.
Noisy Correspondence Learning with Self-Reinforcing Errors Mitigation
Cross-modal retrieval relies on well-matched large-scale datasets that are laborious in practice.
A Survey of Reasoning with Foundation Models
Reasoning, a crucial ability for complex problem-solving, plays a pivotal role in various real-world settings such as negotiation, medical diagnosis, and criminal investigation.
GIR: 3D Gaussian Inverse Rendering for Relightable Scene Factorization
This paper presents GIR, a 3D Gaussian Inverse Rendering method for relightable scene factorization.
Open-sourced Data Ecosystem in Autonomous Driving: the Present and Future
With the continuous maturation and application of autonomous driving technology, a systematic examination of open-source autonomous driving datasets becomes instrumental in fostering the robust evolution of the industry ecosystem.

Generating Action-conditioned Prompts for Open-vocabulary Video Action Recognition
To realize this, we innovatively blend video models with Large Language Models (LLMs) to devise Action-conditioned Prompts.
Layered Rendering Diffusion Model for Zero-Shot Guided Image Synthesis
The LRDiff framework constructs an image-rendering process with multiple layers, each of which applies the vision guidance to instructively estimate the denoising direction for a single object.

GPT4Vis: What Can GPT-4 Do for Zero-shot Visual Recognition?
Our study centers on the evaluation of GPT-4's linguistic and visual capabilities in zero-shot visual recognition tasks: Firstly, we explore the potential of its generated rich textual descriptions across various categories to enhance recognition performance without any training.

GP-NeRF: Generalized Perception NeRF for Context-Aware 3D Scene Understanding
Applying NeRF to downstream perception tasks for scene understanding and representation is becoming increasingly popular.

Disentangled Representation Learning with Transmitted Information Bottleneck
Encoding only the task-related information from the raw data, \ie, disentangled representation learning, can greatly contribute to the robustness and generalizability of models.
HAP: Structure-Aware Masked Image Modeling for Human-Centric Perception
To further capture human characteristics, we propose a structure-invariant alignment loss that enforces different masked views, guided by the human part prior, to be closely aligned for the same image.
Leveraging Vision-Centric Multi-Modal Expertise for 3D Object Detection
Current research is primarily dedicated to advancing the accuracy of camera-only 3D object detectors (apprentice) through the knowledge transferred from LiDAR- or multi-modal-based counterparts (expert).
 Ranked #6 on
3D Object Detection
on nuScenes Camera Only
Ranked #6 on
3D Object Detection
on nuScenes Camera Only

Accelerating Vision Transformers Based on Heterogeneous Attention Patterns
On one hand, different images share more similar attention patterns in early layers than later layers, indicating that the dynamic query-by-key self-attention matrix may be replaced with a static self-attention matrix in early layers.

Forward Flow for Novel View Synthesis of Dynamic Scenes
This paper proposes a neural radiance field (NeRF) approach for novel view synthesis of dynamic scenes using forward warping.
GridFormer: Towards Accurate Table Structure Recognition via Grid Prediction
In this representation, the vertexes and edges of the grid store the localization and adjacency information of the table.
PSDiff: Diffusion Model for Person Search with Iterative and Collaborative Refinement
Dominant Person Search methods aim to localize and recognize query persons in a unified network, which jointly optimizes two sub-tasks, \ie, pedestrian detection and Re-IDentification (ReID).

Unified Frequency-Assisted Transformer Framework for Detecting and Grounding Multi-Modal Manipulation
Moreover, to address the semantic conflicts between image and frequency domains, the forgery-aware mutual module is developed to further enable the effective interaction of disparate image and frequency features, resulting in aligned and comprehensive visual forgery representations.
Unified Pre-training with Pseudo Texts for Text-To-Image Person Re-identification
In this way, the pre-training task and the T2I-ReID task are made consistent with each other on both data and training levels.

VideoGen: A Reference-Guided Latent Diffusion Approach for High Definition Text-to-Video Generation
In this paper, we present VideoGen, a text-to-video generation approach, which can generate a high-definition video with high frame fidelity and strong temporal consistency using reference-guided latent diffusion.

SSMG: Spatial-Semantic Map Guided Diffusion Model for Free-form Layout-to-Image Generation
Despite significant progress in Text-to-Image (T2I) generative models, even lengthy and complex text descriptions still struggle to convey detailed controls.

Boosting Few-shot Action Recognition with Graph-guided Hybrid Matching
Class prototype construction and matching are core aspects of few-shot action recognition.
Group Pose: A Simple Baseline for End-to-End Multi-person Pose Estimation
State-of-the-art solutions adopt the DETR-like framework, and mainly develop the complex decoder, e. g., regarding pose estimation as keypoint box detection and combining with human detection in ED-Pose, hierarchically predicting with pose decoder and joint (keypoint) decoder in PETR.

Multimodal Adaptation of CLIP for Few-Shot Action Recognition
The adapters we design can combine information from video-text multimodal sources for task-oriented spatiotemporal modeling, which is fast, efficient, and has low training costs.
Learning Implicit Entity-object Relations by Bidirectional Generative Alignment for Multimodal NER
Our BGA-MNER consists of \texttt{image2text} and \texttt{text2image} generation with respect to entity-salient content in two modalities.
Enhancing Your Trained DETRs with Box Refinement
We hope our work will bring the attention of the detection community to the localization bottleneck of current DETR-like models and highlight the potential of the RefineBox framework.
CPCM: Contextual Point Cloud Modeling for Weakly-supervised Point Cloud Semantic Segmentation
CMT disentangles the learning of supervised segmentation and unsupervised masked context prediction for effectively learning the very limited labeled points and mass unlabeled points, respectively.

What Can Simple Arithmetic Operations Do for Temporal Modeling?
We conduct comprehensive ablation studies on the instantiation of ATMs and demonstrate that this module provides powerful temporal modeling capability at a low computational cost.
 Ranked #4 on
Action Recognition
on Something-Something V1
Ranked #4 on
Action Recognition
on Something-Something V1

Semi-DETR: Semi-Supervised Object Detection with Detection Transformers
Specifically, we propose a Stage-wise Hybrid Matching strategy that combines the one-to-many assignment and one-to-one assignment strategies to improve the training efficiency of the first stage and thus provide high-quality pseudo labels for the training of the second stage.

Learning Structure-Guided Diffusion Model for 2D Human Pose Estimation
One of the mainstream schemes for 2D human pose estimation (HPE) is learning keypoints heatmaps by a neural network.
Vision Transformer with Attention Map Hallucination and FFN Compaction
Vision Transformer(ViT) is now dominating many vision tasks.
ICDAR 2023 Competition on Structured Text Extraction from Visually-Rich Document Images
It is hoped that this competition will attract many researchers in the field of CV and NLP, and bring some new thoughts to the field of Document AI.
Rethinking the Open-Loop Evaluation of End-to-End Autonomous Driving in nuScenes
Modern autonomous driving systems are typically divided into three main tasks: perception, prediction, and planning.
 Ranked #1 on
Trajectory Planning
on nuScenes
Ranked #1 on
Trajectory Planning
on nuScenes

Multi-Modal 3D Object Detection by Box Matching
Extensive experiments on the nuScenes dataset demonstrate that our method is much more stable in dealing with challenging cases such as asynchronous sensors, misaligned sensor placement, and degenerated camera images than existing fusion methods.
 Ranked #47 on
3D Object Detection
on nuScenes
Ranked #47 on
3D Object Detection
on nuScenes
StyleSync: High-Fidelity Generalized and Personalized Lip Sync in Style-based Generator
Despite recent advances in syncing lip movements with any audio waves, current methods still struggle to balance generation quality and the model's generalization ability.
Exploring Effective Factors for Improving Visual In-Context Learning
By doing this, the model can leverage the diverse knowledge stored in different parts of the model to improve its performance on new tasks.
Task-Oriented Multi-Modal Mutual Leaning for Vision-Language Models
A contrastive loss is employed to align such augmented text and image representations on downstream tasks.
Ambiguity-Resistant Semi-Supervised Learning for Dense Object Detection
It employs a "divide-and-conquer" strategy and separately exploits positives for the classification and localization task, which is more robust to the assignment ambiguity.
 Ranked #1 on
Semi-Supervised Object Detection
on COCO 10% labeled data
(detector metric)
Ranked #1 on
Semi-Supervised Object Detection
on COCO 10% labeled data
(detector metric)
ByteTrackV2: 2D and 3D Multi-Object Tracking by Associating Every Detection Box
We propose a hierarchical data association strategy to mine the true objects in low-score detection boxes, which alleviates the problems of object missing and fragmented trajectories.

CAPE: Camera View Position Embedding for Multi-View 3D Object Detection
In this paper, we address the problem of detecting 3D objects from multi-view images.
Ranked #8 on
3D Object Detection
on nuScenes Camera Only
PSVT: End-to-End Multi-person 3D Pose and Shape Estimation with Progressive Video Transformers
To handle the variances of objects as time proceeds, a novel scheme of progressive decoding is used to update pose and shape queries at each frame.
 Ranked #23 on
3D Human Pose Estimation
on 3DPW
Ranked #23 on
3D Human Pose Estimation
on 3DPW
Delicate Textured Mesh Recovery from NeRF via Adaptive Surface Refinement
Neural Radiance Fields (NeRF) have constituted a remarkable breakthrough in image-based 3D reconstruction.

StrucTexTv2: Masked Visual-Textual Prediction for Document Image Pre-training
Compared to the masked multi-modal modeling methods for document image understanding that rely on both the image and text modalities, StrucTexTv2 models image-only input and potentially deals with more application scenarios free from OCR pre-processing.
 Ranked #1 on
Table Recognition
on WTW
Ranked #1 on
Table Recognition
on WTW


Understanding Self-Supervised Pretraining with Part-Aware Representation Learning
The study is mainly motivated by that random views, used in contrastive learning, and random masked (visible) patches, used in masked image modeling, are often about object parts.

Graph Contrastive Learning for Skeleton-based Action Recognition
In this paper, we propose a graph contrastive learning framework for skeleton-based action recognition (\textit{SkeletonGCL}) to explore the \textit{global} context across all sequences.
 Ranked #9 on
Skeleton Based Action Recognition
on NTU RGB+D
Ranked #9 on
Skeleton Based Action Recognition
on NTU RGB+D
UATVR: Uncertainty-Adaptive Text-Video Retrieval
In the refined embedding space, we represent text-video pairs as probabilistic distributions where prototypes are sampled for matching evaluation.
CFCG: Semi-Supervised Semantic Segmentation via Cross-Fusion and Contour Guidance Supervision
Current state-of-the-art semi-supervised semantic segmentation (SSSS) methods typically adopt pseudo labeling and consistency regularization between multiple learners with different perturbations.

s-Adaptive Decoupled Prototype for Few-Shot Object Detection
To provide precise information for the query image, the prototype is decoupled into task-specific ones, which provide tailored guidance for 'where to look' and 'what to look for', respectively.

Bidirectional Cross-Modal Knowledge Exploration for Video Recognition with Pre-trained Vision-Language Models
In this paper, we propose a novel framework called BIKE, which utilizes the cross-modal bridge to explore bidirectional knowledge: i) We introduce the Video Attribute Association mechanism, which leverages the Video-to-Text knowledge to generate textual auxiliary attributes for complementing video recognition.
 Ranked #1 on
Zero-Shot Action Recognition
on ActivityNet
Ranked #1 on
Zero-Shot Action Recognition
on ActivityNet
Cap4Video: What Can Auxiliary Captions Do for Text-Video Retrieval?
Most existing text-video retrieval methods focus on cross-modal matching between the visual content of videos and textual query sentences.
 Ranked #7 on
Video Retrieval
on VATEX
Ranked #7 on
Video Retrieval
on VATEX

Augmentation Matters: A Simple-yet-Effective Approach to Semi-supervised Semantic Segmentation
Differently, in this work, we follow a standard teacher-student framework and propose AugSeg, a simple and clean approach that focuses mainly on data perturbations to boost the SSS performance.
Masked Lip-Sync Prediction by Audio-Visual Contextual Exploitation in Transformers
This requires masking a large percentage of the original image and seamlessly inpainting it with the aid of audio and reference frames.
Cyclically Disentangled Feature Translation for Face Anti-spoofing
We further extend CDFTN for multi-target domain adaptation by leveraging data from more unlabeled target domains.

Real-time Neural Radiance Talking Portrait Synthesis via Audio-spatial Decomposition
While dynamic Neural Radiance Fields (NeRF) have shown success in high-fidelity 3D modeling of talking portraits, the slow training and inference speed severely obstruct their potential usage.

Instance-specific and Model-adaptive Supervision for Semi-supervised Semantic Segmentation
Relying on the model's performance, iMAS employs a class-weighted symmetric intersection-over-union to evaluate quantitative hardness of each unlabeled instance and supervises the training on unlabeled data in a model-adaptive manner.
Beyond Attentive Tokens: Incorporating Token Importance and Diversity for Efficient Vision Transformers
In this paper, we emphasize the cruciality of diverse global semantics and propose an efficient token decoupling and merging method that can jointly consider the token importance and diversity for token pruning.
 Ranked #4 on
Efficient ViTs
on ImageNet-1K (with DeiT-T)
Ranked #4 on
Efficient ViTs
on ImageNet-1K (with DeiT-T)
CAE v2: Context Autoencoder with CLIP Target
That is to say, the smaller the model, the lower the mask ratio needs to be.

Group DETR v2: Strong Object Detector with Encoder-Decoder Pretraining
The training process consists of self-supervised pretraining and finetuning a ViT-Huge encoder on ImageNet-1K, pretraining the detector on Object365, and finally finetuning it on COCO.
 Ranked #8 on
Object Detection
on COCO test-dev
Ranked #8 on
Object Detection
on COCO test-dev
RTFormer: Efficient Design for Real-Time Semantic Segmentation with Transformer
Recently, transformer-based networks have shown impressive results in semantic segmentation.
 Ranked #2 on
Real-Time Semantic Segmentation
on CamVid
Ranked #2 on
Real-Time Semantic Segmentation
on CamVid

It Takes Two: Masked Appearance-Motion Modeling for Self-supervised Video Transformer Pre-training
In order to guide the encoder to fully excavate spatial-temporal features, two separate decoders are used for two pretext tasks of disentangled appearance and motion prediction.
StyleSwap: Style-Based Generator Empowers Robust Face Swapping
Our core idea is to leverage a style-based generator to empower high-fidelity and robust face swapping, thus the generator's advantage can be adopted for optimizing identity similarity.

NeRF-Loc: Transformer-Based Object Localization Within Neural Radiance Fields
Using current NeRF training tools, a robot can train a NeRF environment model in real-time and, using our algorithm, identify 3D bounding boxes of objects of interest within the NeRF for downstream navigation or manipulation tasks.
TRUST: An Accurate and End-to-End Table structure Recognizer Using Splitting-based Transformers
The Vertex-based Merging Module is capable of aggregating local contextual information between adjacent basic grids, providing the ability to merge basic girds that belong to the same spanning cell accurately.
 Ranked #5 on
Table Recognition
on PubTabNet
Ranked #5 on
Table Recognition
on PubTabNet
CODER: Coupled Diversity-Sensitive Momentum Contrastive Learning for Image-Text Retrieval
We introduce dynamic dictionaries for both modalities to enlarge the scale of image-text pairs, and diversity-sensitiveness is achieved by adaptive negative pair weighting.

Automatic Classification of Bug Reports Based on Multiple Text Information and Reports' Intention
The innovation is that when categorizing bug reports, in addition to using the text information of the report, the intention of the report (i. e. suggestion or explanation) is also considered, thereby improving the performance of the classification.
Rating the Crisis of Online Public Opinion Using a Multi-Level Index System
We propose a method to rate the crisis of online public opinion based on a multi-level index system to evaluate the impact of events objectively.

Group DETR: Fast DETR Training with Group-Wise One-to-Many Assignment
Detection transformer (DETR) relies on one-to-one assignment, assigning one ground-truth object to one prediction, for end-to-end detection without NMS post-processing.
Detecting Deepfake by Creating Spatio-Temporal Regularity Disruption
Specifically, by carefully examining the spatial and temporal properties, we propose to disrupt a real video through a Pseudo-fake Generator and create a wide range of pseudo-fake videos for training.

UFO: Unified Feature Optimization
UFO aims to benefit each single task with a large-scale pretraining on all tasks.


Action Quality Assessment with Temporal Parsing Transformer
Action Quality Assessment(AQA) is important for action understanding and resolving the task poses unique challenges due to subtle visual differences.
Conditional DETR V2: Efficient Detection Transformer with Box Queries
Inspired by Conditional DETR, an improved DETR with fast training convergence, that presented box queries (originally called spatial queries) for internal decoder layers, we reformulate the object query into the format of the box query that is a composition of the embeddings of the reference point and the transformation of the box with respect to the reference point.
Towards Lightweight Super-Resolution with Dual Regression Learning
Nevertheless, it is hard for existing model compression methods to accurately identify the redundant components due to the extremely large SR mapping space.

Paint and Distill: Boosting 3D Object Detection with Semantic Passing Network
In this work, we propose a novel semantic passing framework, named SPNet, to boost the performance of existing lidar-based 3D detection models with the guidance of rich context painting, with no extra computation cost during inference.
Delving into Sequential Patches for Deepfake Detection
Recent advances in face forgery techniques produce nearly visually untraceable deepfake videos, which could be leveraged with malicious intentions.
Singular Value Fine-tuning: Few-shot Segmentation requires Few-parameters Fine-tuning
In this paper, we rethink the paradigm and explore a new regime: {\em fine-tuning a small part of parameters in the backbone}.
 Ranked #8 on
Few-Shot Semantic Segmentation
on COCO-20i (1-shot)
Ranked #8 on
Few-Shot Semantic Segmentation
on COCO-20i (1-shot)

MaskOCR: Text Recognition with Masked Encoder-Decoder Pretraining
Specifically, we transform text data into synthesized text images to unify the data modalities of vision and language, and enhance the language modeling capability of the sequence decoder using a proposed masked image-language modeling scheme.


Few-Shot Font Generation by Learning Fine-Grained Local Styles
Instead of explicitly disentangling global or component-wise modeling, the cross-attention mechanism can attend to the right local styles in the reference glyphs and aggregate the reference styles into a fine-grained style representation for the given content glyphs.
Results of the NeurIPS'21 Challenge on Billion-Scale Approximate Nearest Neighbor Search
The outcome of the competition was ranked leaderboards of algorithms in each track based on recall at a query throughput threshold.
Few-Shot Head Swapping in the Wild
Particularly, seamless blending is achieved with the help of a Semantic-Guided Color Reference Creation procedure and a Blending UNet.
Human-Object Interaction Detection via Disentangled Transformer
To associate the predictions of disentangled decoders, we first generate a unified representation for HOI triplets with a base decoder, and then utilize it as input feature of each disentangled decoder.
GitNet: Geometric Prior-based Transformation for Birds-Eye-View Segmentation
Birds-eye-view (BEV) semantic segmentation is critical for autonomous driving for its powerful spatial representation ability.
Implicit Sample Extension for Unsupervised Person Re-Identification
Specifically, we generate support samples from actual samples and their neighbouring clusters in the embedding space through a progressive linear interpolation (PLI) strategy.
DaViT: Dual Attention Vision Transformers
We show that these two self-attentions complement each other: (i) since each channel token contains an abstract representation of the entire image, the channel attention naturally captures global interactions and representations by taking all spatial positions into account when computing attention scores between channels; (ii) the spatial attention refines the local representations by performing fine-grained interactions across spatial locations, which in turn helps the global information modeling in channel attention.


ViSTA: Vision and Scene Text Aggregation for Cross-Modal Retrieval
Visual appearance is considered to be the most important cue to understand images for cross-modal retrieval, while sometimes the scene text appearing in images can provide valuable information to understand the visual semantics.
 Ranked #10 on
Cross-Modal Retrieval
on Flickr30k
(using extra training data)
Ranked #10 on
Cross-Modal Retrieval
on Flickr30k
(using extra training data)
Efficient Video Segmentation Models with Per-frame Inference
To this end, we perform inference at each frame.

Context Autoencoder for Self-Supervised Representation Learning
The pretraining tasks include two tasks: masked representation prediction - predict the representations for the masked patches, and masked patch reconstruction - reconstruct the masked patches.

Expressive Talking Head Generation With Granular Audio-Visual Control
Generating expressive talking heads is essential for creating virtual humans.

HRFormer: High-Resolution Vision Transformer for Dense Predict
We present a High-Resolution Transformer (HRFormer) that learns high-resolution representations for dense prediction tasks, in contrast to the original Vision Transformer that produces low-resolution representations and has high memory and computational cost.
SPANN: Highly-efficient Billion-scale Approximate Nearest Neighbor Search
It stores the centroid points of the posting lists in the memory and the large posting lists in the disk.
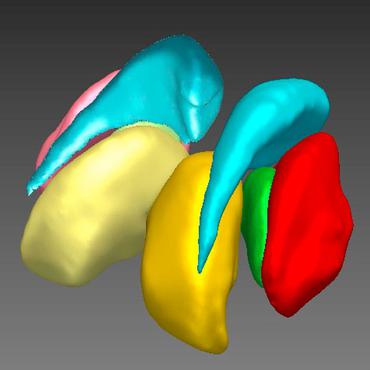
Whole Brain Segmentation with Full Volume Neural Network
To address these issues, we propose to adopt a full volume framework, which feeds the full volume brain image into the segmentation network and directly outputs the segmentation result for the whole brain volume.
HRFormer: High-Resolution Transformer for Dense Prediction
We present a High-Resolution Transformer (HRFormer) that learns high-resolution representations for dense prediction tasks, in contrast to the original Vision Transformer that produces low-resolution representations and has high memory and computational cost.
 Ranked #3 on
Pose Estimation
on AIC
Ranked #3 on
Pose Estimation
on AIC
Realistic Image Synthesis with Configurable 3D Scene Layouts
Our approach takes a 3D scene with semantic class labels as input and trains a 3D scene painting network that synthesizes color values for the input 3D scene.
Conditional DETR for Fast Training Convergence
Our approach, named conditional DETR, learns a conditional spatial query from the decoder embedding for decoder multi-head cross-attention.
Content-Aware Convolutional Neural Networks
In practice, the convolutional operation on some of the windows (e. g., smooth windows that contain very similar pixels) can be very redundant and may introduce noises into the computation.
Cross-Modal Attention Consistency for Video-Audio Unsupervised Learning
Cross-modal correlation provides an inherent supervision for video unsupervised representation learning.
On the Connection between Local Attention and Dynamic Depth-wise Convolution
Sparse connectivity: there is no connection across channels, and each position is connected to the positions within a small local window.
Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision
Our approach imposes the consistency on two segmentation networks perturbed with different initialization for the same input image.
 Ranked #2 on
Semi-Supervised Semantic Segmentation
on WoodScape
Ranked #2 on
Semi-Supervised Semantic Segmentation
on WoodScape
SPANN: Highly-efficient Billion-scale Approximate Nearest Neighborhood Search
It stores the centroid points of the posting lists in the memory and the large posting lists in the disk.
Lite-HRNet: A Lightweight High-Resolution Network
We introduce a lightweight unit, conditional channel weighting, to replace costly pointwise (1x1) convolutions in shuffle blocks.
 Ranked #33 on
Pose Estimation
on COCO test-dev
(using extra training data)
Ranked #33 on
Pose Estimation
on COCO test-dev
(using extra training data)
Bottom-Up Human Pose Estimation Via Disentangled Keypoint Regression
Our motivation is that regressing keypoint positions accurately needs to learn representations that focus on the keypoint regions.

Learning Versatile Neural Architectures by Propagating Network Codes
(4) Thorough studies of NCP on inter-, cross-, and intra-tasks highlight the importance of cross-task neural architecture design, i. e., multitask neural architectures and architecture transferring between different tasks.

Boosting Adversarial Transferability through Enhanced Momentum
Various momentum iterative gradient-based methods are shown to be effective to improve the adversarial transferability.
Admix: Enhancing the Transferability of Adversarial Attacks
We investigate in this direction and observe that existing transformations are all applied on a single image, which might limit the adversarial transferability.
Consistent Instance Classification for Unsupervised Representation Learning
The proposed consistent instance classification (ConIC) approach simultaneously optimizes the classification loss and an additional consistency loss explicitly penalizing the feature dissimilarity between the augmented views from the same instance.


Improving Person Re-identification with Iterative Impression Aggregation
Not only does such a simple method improve the performance of the baseline models, it also achieves comparable performance with latest advanced re-ranking methods.
Informative Dropout for Robust Representation Learning: A Shape-bias Perspective
Specifically, we discriminate texture from shape based on local self-information in an image, and adopt a Dropout-like algorithm to decorrelate the model output from the local texture.
Distillation Guided Residual Learning for Binary Convolutional Neural Networks
We observe that, this performance gap leads to substantial residuals between intermediate feature maps of BCNN and FCNN.
SegFix: Model-Agnostic Boundary Refinement for Segmentation
We present a model-agnostic post-processing scheme to improve the boundary quality for the segmentation result that is generated by any existing segmentation model.
Point-Set Anchors for Object Detection, Instance Segmentation and Pose Estimation
A recent approach for object detection and human pose estimation is to regress bounding boxes or human keypoints from a central point on the object or person.
Bottom-Up Human Pose Estimation by Ranking Heatmap-Guided Adaptive Keypoint Estimates
The typical bottom-up human pose estimation framework includes two stages, keypoint detection and grouping.
Weakly-Supervised Action Localization by Generative Attention Modeling
By maximizing the conditional probability with respect to the attention, the action and non-action frames are well separated.

 Weakly Supervised Action Localization
Weakly-supervised Temporal Action Localization
+1
Weakly Supervised Action Localization
Weakly-supervised Temporal Action Localization
+1
Closed-loop Matters: Dual Regression Networks for Single Image Super-Resolution
Extensive experiments with paired training data and unpaired real-world data demonstrate our superiority over existing methods.
Efficient Semantic Video Segmentation with Per-frame Inference
For semantic segmentation, most existing real-time deep models trained with each frame independently may produce inconsistent results for a video sequence.
 Ranked #2 on
Video Semantic Segmentation
on CamVid
Ranked #2 on
Video Semantic Segmentation
on CamVid

Segmentation Transformer: Object-Contextual Representations for Semantic Segmentation
We empirically demonstrate that the proposed approach achieves competitive performance on various challenging semantic segmentation benchmarks: Cityscapes, ADE20K, LIP, PASCAL-Context, and COCO-Stuff.
 Ranked #5 on
Semantic Segmentation
on LIP val
Ranked #5 on
Semantic Segmentation
on LIP val
Cross View Fusion for 3D Human Pose Estimation
It consists of two separate steps: (1) estimating the 2D poses in multi-view images and (2) recovering the 3D poses from the multi-view 2D poses.
 Ranked #6 on
3D Human Pose Estimation
on Total Capture
Ranked #6 on
3D Human Pose Estimation
on Total Capture

Global-Local Temporal Representations For Video Person Re-Identification
The long-term relations are captured by a temporal self-attention model to alleviate the occlusions and noises in video sequences.

HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation
HigherHRNet even surpasses all top-down methods on CrowdPose test (67. 6% AP), suggesting its robustness in crowded scene.
 Ranked #2 on
Pose Estimation
on UAV-Human
Ranked #2 on
Pose Estimation
on UAV-Human
Deep High-Resolution Representation Learning for Visual Recognition
High-resolution representations are essential for position-sensitive vision problems, such as human pose estimation, semantic segmentation, and object detection.
Ranked #1 on
Object Detection
on COCO test-dev
(Hardware Burden metric)


Interlaced Sparse Self-Attention for Semantic Segmentation
There are two successive attention modules each estimating a sparse affinity matrix.
MMDetection: Open MMLab Detection Toolbox and Benchmark
In this paper, we introduce the various features of this toolbox.
Group Re-Identification with Multi-grained Matching and Integration
The task of re-identifying groups of people underdifferent camera views is an important yet less-studied problem. Group re-identification (Re-ID) is a very challenging task sinceit is not only adversely affected by common issues in traditionalsingle object Re-ID problems such as viewpoint and human posevariations, but it also suffers from changes in group layout andgroup membership.
High-Resolution Representations for Labeling Pixels and Regions
The proposed approach achieves superior results to existing single-model networks on COCO object detection.
Ranked #7 on
Semantic Segmentation
on LIP val

Structured Knowledge Distillation for Dense Prediction
Here we propose to distill structured knowledge from large networks to compact networks, taking into account the fact that dense prediction is a structured prediction problem.

Deep High-Resolution Representation Learning for Human Pose Estimation
We start from a high-resolution subnetwork as the first stage, gradually add high-to-low resolution subnetworks one by one to form more stages, and connect the mutli-resolution subnetworks in parallel.
 Ranked #1 on
Pose Estimation
on BRACE
Ranked #1 on
Pose Estimation
on BRACE
Collaborative Quantization for Cross-Modal Similarity Search
Cross-modal similarity search is a problem about designing a search system supporting querying across content modalities, e. g., using an image to search for texts or using a text to search for images.
Supervised Quantization for Similarity Search
In this paper, we address the problem of searching for semantically similar images from a large database.
Deep Triplet Quantization
We propose Deep Triplet Quantization (DTQ), a novel approach to learning deep quantization models from the similarity triplets.
 Ranked #1 on
Image Retrieval
on NUS-WIDE
Ranked #1 on
Image Retrieval
on NUS-WIDE

Disparity-preserved Deep Cross-platform Association for Cross-platform Video Recommendation
However, there remain two unsolved challenges: i) there exist inconsistencies in cross-platform association due to platform-specific disparity, and ii) data from distinct platforms may have different semantic granularities.
Weakly Supervised Dense Event Captioning in Videos
Dense event captioning aims to detect and describe all events of interest contained in a video.
Accelerating Deep Neural Networks with Spatial Bottleneck Modules
This paper presents an efficient module named spatial bottleneck for accelerating the convolutional layers in deep neural networks.
OCNet: Object Context Network for Scene Parsing
To capture richer context information, we further combine our interlaced sparse self-attention scheme with the conventional multi-scale context schemes including pyramid pooling~\citep{zhao2017pyramid} and atrous spatial pyramid pooling~\citep{chen2018deeplab}.
![]() Ranked #9 on
Semantic Segmentation
on Trans10K
Ranked #9 on
Semantic Segmentation
on Trans10K
IGCV3: Interleaved Low-Rank Group Convolutions for Efficient Deep Neural Networks
In this paper, we are interested in building lightweight and efficient convolutional neural networks.
Interleaved Structured Sparse Convolutional Neural Networks
In this paper, we study the problem of designing efficient convolutional neural network architectures with the interest in eliminating the redundancy in convolution kernels.
Weakly-Supervised Semantic Segmentation Network With Deep Seeded Region Growing
Inspired by the traditional image segmentation methods of seeded region growing, we propose to train a semantic segmentation network starting from the discriminative regions and progressively increase the pixel-level supervision using by seeded region growing.
 Ranked #38 on
Weakly-Supervised Semantic Segmentation
on COCO 2014 val
(using extra training data)
Ranked #38 on
Weakly-Supervised Semantic Segmentation
on COCO 2014 val
(using extra training data)
Part-Aligned Bilinear Representations for Person Re-identification
We propose a novel network that learns a part-aligned representation for person re-identification.
 Ranked #4 on
Person Re-Identification
on UAV-Human
Ranked #4 on
Person Re-Identification
on UAV-Human
IGCV$2$: Interleaved Structured Sparse Convolutional Neural Networks
In this paper, we study the problem of designing efficient convolutional neural network architectures with the interest in eliminating the redundancy in convolution kernels.
Object Detection in Videos by High Quality Object Linking
In particular, our method improves results by 8. 8% over the static image detector for fast moving objects.
LVreID: Person Re-Identification with Long Sequence Videos
This paper mainly establishes a large-scale Long sequence Video database for person re-IDentification (LVreID).
S4Net: Single Stage Salient-Instance Segmentation
Taking into account the category-independent property of each target, we design a single stage salient instance segmentation framework, with a novel segmentation branch.
Global versus Localized Generative Adversarial Nets
In this paper, we present a novel localized Generative Adversarial Net (GAN) to learn on the manifold of real data.
Interleaved Group Convolutions
The main point lies in a novel building block, a pair of two successive interleaved group convolutions: primary group convolution and secondary group convolution.
Ensemble Diffusion for Retrieval
This stimulates a great research interest of considering similarity fusion in the framework of diffusion process (i. e., fusion with diffusion) for robust retrieval.

Human Pose Estimation using Global and Local Normalization
We present a two-stage normalization scheme, human body normalization and limb normalization, to make the distribution of the relative joint locations compact, resulting in easier learning of convolutional spatial models and more accurate pose estimation.
Rethink ReLU to Training Better CNNs
Most of convolutional neural networks share the same characteristic: each convolutional layer is followed by a nonlinear activation layer where Rectified Linear Unit (ReLU) is the most widely used.
Deeply-Learned Part-Aligned Representations for Person Re-Identification
In this paper, we address the problem of person re-identification, which refers to associating the persons captured from different cameras.
 Ranked #106 on
Person Re-Identification
on Market-1501
Ranked #106 on
Person Re-Identification
on Market-1501
Orthogonal and Idempotent Transformations for Learning Deep Neural Networks
Identity transformations, used as skip-connections in residual networks, directly connect convolutional layers close to the input and those close to the output in deep neural networks, improving information flow and thus easing the training.
Interleaved Group Convolutions for Deep Neural Networks
The main point lies in a novel building block, a pair of two successive interleaved group convolutions: primary group convolution and secondary group convolution.
Learning Correspondence Structures for Person Re-identification
We first introduce a boosting-based approach to learn a correspondence structure which indicates the patch-wise matching probabilities between images from a target camera pair.
Deep Convolutional Neural Networks with Merge-and-Run Mappings
A deep residual network, built by stacking a sequence of residual blocks, is easy to train, because identity mappings skip residual branches and thus improve information flow.
Geometric Neural Phrase Pooling: Modeling the Spatial Co-occurrence of Neurons
For this, we consider the neurons in the hidden layer as neural words, and construct a set of geometric neural phrases on top of them.
A Survey on Learning to Hash
In this paper, we present a comprehensive survey of the learning to hash algorithms, categorize them according to the manners of preserving the similarities into: pairwise similarity preserving, multiwise similarity preserving, implicit similarity preserving, as well as quantization, and discuss their relations.
Deeply-Fused Nets
Second, in our suggested fused net formed by one deep and one shallow base networks, the flows of the information from the earlier intermediate layer of the deep base network to the output and from the input to the later intermediate layer of the deep base network are both improved.
DisturbLabel: Regularizing CNN on the Loss Layer
During a long period of time we are combating over-fitting in the CNN training process with model regularization, including weight decay, model averaging, data augmentation, etc.
InterActive: Inter-Layer Activeness Propagation
An increasing number of computer vision tasks can be tackled with deep features, which are the intermediate outputs of a pre-trained Convolutional Neural Network.
Good Practice in CNN Feature Transfer
The objective of this paper is the effective transfer of the Convolutional Neural Network (CNN) feature in image search and classification.
A diffusion and clustering-based approach for finding coherent motions and understanding crowd scenes
These semantic regions can be used to recognize pre-defined activities in crowd scenes.
RIDE: Reversal Invariant Descriptor Enhancement
In many fine-grained object recognition datasets, image orientation (left/right) might vary from sample to sample.

Scalable Person Re-Identification: A Benchmark
As a minor contribution, inspired by recent advances in large-scale image search, this paper proposes an unsupervised Bag-of-Words descriptor.
 Ranked #90 on
Person Re-Identification
on DukeMTMC-reID
Ranked #90 on
Person Re-Identification
on DukeMTMC-reID
DeepSaliency: Multi-Task Deep Neural Network Model for Salient Object Detection
A key problem in salient object detection is how to effectively model the semantic properties of salient objects in a data-driven manner.
Co-Saliency Detection via Looking Deep and Wide
In the proposed framework, the wide and deep information are explored for the object proposal windows extracted in each image, and the co-saliency scores are calculated by integrating the intra-image contrast and intra group consistency via a principled Bayesian formulation.

Similarity Learning on an Explicit Polynomial Kernel Feature Map for Person Re-Identification
We follow the learning-to-rank methodology and learn a similarity function to maximize the difference between the similarity scores of matched and unmatched images for a same person.
Sparse Composite Quantization
The benefit is that the distance evaluation between the query and the dictionary element (a sparse vector) is accelerated using the efficient sparse vector operation, and thus the cost of distance table computation is reduced a lot.
Person Re-identification with Correspondence Structure Learning
This paper addresses the problem of handling spatial misalignments due to camera-view changes or human-pose variations in person re-identification.
Group $K$-Means
We study how to learn multiple dictionaries from a dataset, and approximate any data point by the sum of the codewords each chosen from the corresponding dictionary.
Salient Object Detection: A Discriminative Regional Feature Integration Approach
Our method, which is based on multi-level image segmentation, utilizes the supervised learning approach to map the regional feature vector to a saliency score.
Deep Regression for Face Alignment
In this paper, we present a deep regression approach for face alignment.
Hashing for Similarity Search: A Survey
Similarity search (nearest neighbor search) is a problem of pursuing the data items whose distances to a query item are the smallest from a large database.
Low-rank SIFT: An Affine Invariant Feature for Place Recognition
As an extension of SIFT, our method seeks to add prior to solve the ill-posed affine parameter estimation problem and normalizes them directly, and is applicable to objects with regular structures.
Inner Product Similarity Search using Compositional Codes
This paper addresses the nearest neighbor search problem under inner product similarity and introduces a compact code-based approach.
Orientational Pyramid Matching for Recognizing Indoor Scenes
The novelty lies in that OPM uses the 3D orientations to form the pyramid and produce the pooling regions, which is unlike SPM that uses the spatial positions to form the pyramid.
Optimized Cartesian $K$-Means
In OCKM, multiple sub codewords are used to encode the subvector of a data point in a subspace.
Fast Neighborhood Graph Search using Cartesian Concatenation
This structure augments the neighborhood graph with a bridge graph.
Fast Approximate $K$-Means via Cluster Closures
Traditional $k$-means is an iterative algorithm---in each iteration new cluster centers are computed and each data point is re-assigned to its nearest center.
Scalable $k$-NN graph construction
The $k$-NN graph has played a central role in increasingly popular data-driven techniques for various learning and vision tasks; yet, finding an efficient and effective way to construct $k$-NN graphs remains a challenge, especially for large-scale high-dimensional data.
Hybrid Affinity Propagation
We formulate this problem as finding a few image exemplars to represent the image set semantically and visually, and solve it in a hybrid way by exploiting both visual and textual information associated with images.
Supervised Kernel Descriptors for Visual Recognition
In visual recognition tasks, the design of low level image feature representation is fundamental.
