Search Results for author:
Found 19 papers, 17 papers with code
LLM-Seg: Bridging Image Segmentation and Large Language Model Reasoning
In this work, we delve into reasoning segmentation, a novel task that enables segmentation system to reason and interpret implicit user intention via large language model reasoning and then segment the corresponding target.


Gaussian Grouping: Segment and Edit Anything in 3D Scenes
To address this issue, we propose Gaussian Grouping, which extends Gaussian Splatting to jointly reconstruct and segment anything in open-world 3D scenes.


Stable Segment Anything Model
Thus, our solution, termed Stable-SAM, offers several advantages: 1) improved SAM's segmentation stability across a wide range of prompt qualities, while 2) retaining SAM's powerful promptable segmentation efficiency and generality, with 3) minimal learnable parameters (0. 08 M) and fast adaptation (by 1 training epoch).
Cascade-DETR: Delving into High-Quality Universal Object Detection
While dominating on the COCO benchmark, recent Transformer-based detection methods are not competitive in diverse domains.
Segment Anything Meets Point Tracking
The Segment Anything Model (SAM) has established itself as a powerful zero-shot image segmentation model, enabled by efficient point-centric annotation and prompt-based models.

Segment Anything in High Quality
HQ-SAM is only trained on the introduced detaset of 44k masks, which takes only 4 hours on 8 GPUs.
 Ranked #1 on
Zero-Shot Instance Segmentation
on LVIS v1.0 val
Ranked #1 on
Zero-Shot Instance Segmentation
on LVIS v1.0 val
OVTrack: Open-Vocabulary Multiple Object Tracking
This leaves contemporary MOT methods limited to a small set of pre-defined object categories.

Mask-Free Video Instance Segmentation
A consistency loss is then enforced on the found matches.



Occlusion-Aware Instance Segmentation via BiLayer Network Architectures
Unlike previous instance segmentation methods, we model image formation as a composition of two overlapping layers, and propose Bilayer Convolutional Network (BCNet), where the top layer detects occluding objects (occluders) and the bottom layer infers partially occluded instances (occludees).
Video Mask Transfiner for High-Quality Video Instance Segmentation
While Video Instance Segmentation (VIS) has seen rapid progress, current approaches struggle to predict high-quality masks with accurate boundary details.
 Ranked #1 on
Video Instance Segmentation
on HQ-YTVIS
Ranked #1 on
Video Instance Segmentation
on HQ-YTVIS

Mask Transfiner for High-Quality Instance Segmentation
Instead of operating on regular dense tensors, our Mask Transfiner decomposes and represents the image regions as a quadtree.
 Ranked #1 on
Instance Segmentation
on BDD100K val
Ranked #1 on
Instance Segmentation
on BDD100K val
Occlusion-Aware Video Object Inpainting
To facilitate this new research, we construct the first large-scale video object inpainting benchmark YouTube-VOI to provide realistic occlusion scenarios with both occluded and visible object masks available.
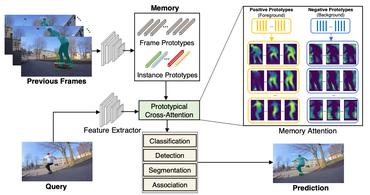
Prototypical Cross-Attention Networks for Multiple Object Tracking and Segmentation
We propose Prototypical Cross-Attention Network (PCAN), capable of leveraging rich spatio-temporal information for online multiple object tracking and segmentation.
 Ranked #1 on
Video Instance Segmentation
on BDD100K val
Ranked #1 on
Video Instance Segmentation
on BDD100K val
 Multi-Object Tracking and Segmentation
Multi-Object Tracking and Segmentation
 Multiple Object Track and Segmentation
+3
Multiple Object Track and Segmentation
+3
Deep Occlusion-Aware Instance Segmentation with Overlapping BiLayers
Segmenting highly-overlapping objects is challenging, because typically no distinction is made between real object contours and occlusion boundaries.
 Ranked #1 on
Instance Segmentation
on KINS
Ranked #1 on
Instance Segmentation
on KINS
GSNet: Joint Vehicle Pose and Shape Reconstruction with Geometrical and Scene-aware Supervision
GSNet utilizes a unique four-way feature extraction and fusion scheme and directly regresses 6DoF poses and shapes in a single forward pass.
 Ranked #1 on
Autonomous Driving
on ApolloCar3D
Ranked #1 on
Autonomous Driving
on ApolloCar3D


Commonality-Parsing Network across Shape and Appearance for Partially Supervised Instance Segmentation
We propose to learn the underlying class-agnostic commonalities that can be generalized from mask-annotated categories to novel categories.
 Ranked #79 on
Instance Segmentation
on COCO test-dev
Ranked #79 on
Instance Segmentation
on COCO test-dev
Cascaded deep monocular 3D human pose estimation with evolutionary training data
End-to-end deep representation learning has achieved remarkable accuracy for monocular 3D human pose estimation, yet these models may fail for unseen poses with limited and fixed training data.
 Ranked #13 on
Weakly-supervised 3D Human Pose Estimation
on Human3.6M
Ranked #13 on
Weakly-supervised 3D Human Pose Estimation
on Human3.6M

Reflective Decoding Network for Image Captioning
State-of-the-art image captioning methods mostly focus on improving visual features, less attention has been paid to utilizing the inherent properties of language to boost captioning performance.
 Ranked #4 on
Image Captioning
on MS COCO
Ranked #4 on
Image Captioning
on MS COCO

Memory-Attended Recurrent Network for Video Captioning
Typical techniques for video captioning follow the encoder-decoder framework, which can only focus on one source video being processed.
