Search Results for author:
Found 42 papers, 15 papers with code
Empowering Large Language Models on Robotic Manipulation with Affordance Prompting
While large language models (LLMs) are successful in completing various language processing tasks, they easily fail to interact with the physical world by generating control sequences properly.
VSFormer: Visual-Spatial Fusion Transformer for Correspondence Pruning
Then, we model these visual cues and correspondences by a joint visual-spatial fusion module, simultaneously embedding visual cues into correspondences for pruning.
Pre-Trained Large Language Models for Industrial Control
2)~How well can GPT-4 generalize to different scenarios for HVAC control?
Learning Multi-Agent Intention-Aware Communication for Optimal Multi-Order Execution in Finance
Order execution is a fundamental task in quantitative finance, aiming at finishing acquisition or liquidation for a number of trading orders of the specific assets.
A Versatile Multi-Agent Reinforcement Learning Benchmark for Inventory Management
Multi-agent reinforcement learning (MARL) models multiple agents that interact and learn within a shared environment.

Asking Before Acting: Gather Information in Embodied Decision Making with Language Models
With strong capabilities of reasoning and a broad understanding of the world, Large Language Models (LLMs) have demonstrated immense potential in building versatile embodied decision-making agents capable of executing a wide array of tasks.
Towards Generalizable Reinforcement Learning for Trade Execution
To evaluate our algorithms, we also implement a carefully designed simulator based on historical limit order book (LOB) data to provide a high-fidelity benchmark for different algorithms.
H-TSP: Hierarchically Solving the Large-Scale Travelling Salesman Problem
We propose an end-to-end learning framework based on hierarchical reinforcement learning, called H-TSP, for addressing the large-scale Travelling Salesman Problem (TSP).
Pointerformer: Deep Reinforced Multi-Pointer Transformer for the Traveling Salesman Problem
Traveling Salesman Problem (TSP), as a classic routing optimization problem originally arising in the domain of transportation and logistics, has become a critical task in broader domains, such as manufacturing and biology.
Deep Implicit Distribution Alignment Networks for Cross-Corpus Speech Emotion Recognition
In this paper, we propose a novel deep transfer learning method called deep implicit distribution alignment networks (DIDAN) to deal with cross-corpus speech emotion recognition (SER) problem, in which the labeled training (source) and unlabeled testing (target) speech signals come from different corpora.
An Adaptive Deep RL Method for Non-Stationary Environments with Piecewise Stable Context
One of the key challenges in deploying RL to real-world applications is to adapt to variations of unknown environment contexts, such as changing terrains in robotic tasks and fluctuated bandwidth in congestion control.
Multi-Agent Reinforcement Learning with Shared Resources for Inventory Management
In this paper, we consider the inventory management (IM) problem where we need to make replenishment decisions for a large number of stock keeping units (SKUs) to balance their supply and demand.
TD3 with Reverse KL Regularizer for Offline Reinforcement Learning from Mixed Datasets
There are two challenges for this setting: 1) The optimal trade-off between optimizing the RL signal and the behavior cloning (BC) signal changes on different states due to the variation of the action coverage induced by different behavior policies.
Inspector: Pixel-Based Automated Game Testing via Exploration, Detection, and Investigation
In this work, we propose using only screenshots/pixels as input for automated game testing and build a general game testing agent, Inspector, that can be easily applied to different games without deep integration with games.
Tiered Reinforcement Learning: Pessimism in the Face of Uncertainty and Constant Regret
We propose a new learning framework that captures the tiered structure of many real-world user-interaction applications, where the users can be divided into two groups based on their different tolerance on exploration risks and should be treated separately.
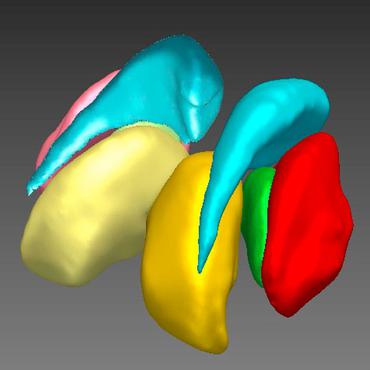
Fetal Brain Tissue Annotation and Segmentation Challenge Results
Automatic segmentation of the developing fetal brain is a vital step in the quantitative analysis of prenatal neurodevelopment both in the research and clinical context.
Towards Deployment-Efficient Reinforcement Learning: Lower Bound and Optimality
Deployment efficiency is an important criterion for many real-world applications of reinforcement learning (RL).
ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
A unified framework named ERNIE 3. 0 was recently proposed for pre-training large-scale knowledge enhanced models and trained a model with 10 billion parameters.

Curriculum Offline Imitating Learning
However, IL is usually limited in the capability of the behavioral policy and tends to learn a mediocre behavior from the dataset collected by the mixture of policies.
Curriculum Offline Imitation Learning
However, IL is usually limited in the capability of the behavioral policy and tends to learn a mediocre behavior from the dataset collected by the mixture of policies.
Object-Aware Regularization for Addressing Causal Confusion in Imitation Learning
Behavioral cloning has proven to be effective for learning sequential decision-making policies from expert demonstrations.
Distributional Reinforcement Learning for Multi-Dimensional Reward Functions
To fully inherit the benefits of distributional RL and hybrid reward architectures, we introduce Multi-Dimensional Distributional DQN (MD3QN), which extends distributional RL to model the joint return distribution from multiple reward sources.
 Distributional Reinforcement Learning
Distributional Reinforcement Learning
 reinforcement-learning
+1
reinforcement-learning
+1
Multi-Agent Reinforcement Learning with Shared Resource in Inventory Management
We consider inventory management (IM) problem for a single store with a large number of SKUs (stock keeping units) in this paper, where we need to make replenishment decisions for each SKU to balance its supply and demand.
Concept-Based Label Embedding via Dynamic Routing for Hierarchical Text Classification
In this paper, we propose a novel concept-based label embedding method that can explicitly represent the concept and model the sharing mechanism among classes for the hierarchical text classification.

Return-Based Contrastive Representation Learning for Reinforcement Learning
Recently, various auxiliary tasks have been proposed to accelerate representation learning and improve sample efficiency in deep reinforcement learning (RL).

Design and Commissioning of the PandaX-4T Cryogenic Distillation System for Krypton and Radon Removal
An online cryogenic distillation system for the removal of krypton and radon from xenon was designed and constructed for PandaX-4T, a highly sensitive dark matter detection experiment.
Instrumentation and Detectors High Energy Physics - Experiment
RD$^2$: Reward Decomposition with Representation Decomposition
In this work, we propose a set of novel reward decomposition principles by constraining uniqueness and compactness of different state features/representations relevant to different sub-rewards.
A Multi-stream Convolutional Neural Network for Micro-expression Recognition Using Optical Flow and EVM
On the other hand, some methods based on deep learning also cannot get high accuracy due to problems such as the imbalance of databases.
Micro Expression Recognition
Micro-Expression Recognition
+1
Tensor Perturbations and Thick Branes in Higher-dimensional $f(R)$ Gravity
At last, the effective potential of the Kaluza-Klein modes of the graviton is discussed for the two solved $f(R)$ models in higher dimensions.
High Energy Physics - Theory General Relativity and Quantum Cosmology
Multi-Site Infant Brain Segmentation Algorithms: The iSeg-2019 Challenge
Deep learning-based methods have achieved state-of-the-art performance; however, one of major limitations is that the learning-based methods may suffer from the multi-site issue, that is, the models trained on a dataset from one site may not be applicable to the datasets acquired from other sites with different imaging protocols/scanners.
Suphx: Mastering Mahjong with Deep Reinforcement Learning
Artificial Intelligence (AI) has achieved great success in many domains, and game AI is widely regarded as its beachhead since the dawn of AI.
Distributional Reward Decomposition for Reinforcement Learning
Many reinforcement learning (RL) tasks have specific properties that can be leveraged to modify existing RL algorithms to adapt to those tasks and further improve performance, and a general class of such properties is the multiple reward channel.
Fully Parameterized Quantile Function for Distributional Reinforcement Learning
The key challenge in practical distributional RL algorithms lies in how to parameterize estimated distributions so as to better approximate the true continuous distribution.
 Ranked #3 on
Atari Games
on Atari 2600 Skiing
(using extra training data)
Ranked #3 on
Atari Games
on Atari 2600 Skiing
(using extra training data)
Demonstration Actor Critic
One approach leverages demonstration data in a supervised manner, which is simple and direct, but can only provide supervision signal over those states seen in the demonstrations.
Independence-aware Advantage Estimation
Most of existing advantage function estimation methods in reinforcement learning suffer from the problem of high variance, which scales unfavorably with the time horizon.
Reinforcement Learning for Relation Classification from Noisy Data
In this paper, we propose a novel model for relation classification at the sentence level from noisy data.

Efficient Sequence Learning with Group Recurrent Networks
Recurrent neural networks have achieved state-of-the-art results in many artificial intelligence tasks, such as language modeling, neural machine translation, speech recognition and so on.

Limits on Axion Couplings from the first 80-day data of PandaX-II Experiment
We report new searches for the solar axions and galactic axion-like dark matter particles, using the first low-background data from PandaX-II experiment at China Jinping Underground Laboratory, corresponding to a total exposure of about $2. 7\times 10^4$ kg$\cdot$day.
High Energy Physics - Experiment Solar and Stellar Astrophysics High Energy Physics - Phenomenology
Adversarial Neural Machine Translation
The goal of the adversary is to differentiate the translation result generated by the NMT model from that by human.





Somoclu: An Efficient Parallel Library for Self-Organizing Maps
Somoclu is a massively parallel tool for training self-organizing maps on large data sets written in C++.
