Search Results for author:
Found 111 papers, 46 papers with code
Wild Face Anti-Spoofing Challenge 2023: Benchmark and Results
Leveraging the WFAS dataset and Protocol 1 (Known-Type), we host the Wild Face Anti-Spoofing Challenge at the CVPR2023 workshop.


A Dataset and Benchmark for Large-scale Multi-modal Face Anti-spoofing
To facilitate face anti-spoofing research, we introduce a large-scale multi-modal dataset, namely CASIA-SURF, which is the largest publicly available dataset for face anti-spoofing in terms of both subjects and visual modalities.
Bi-Directional ConvLSTM U-Net with Densley Connected Convolutions
To strengthen feature propagation and encourage feature reuse, we use densely connected convolutions in the last convolutional layer of the encoding path.
 Ranked #1 on
Lung Nodule Segmentation
on Lung Nodule
Ranked #1 on
Lung Nodule Segmentation
on Lung Nodule

Multi-level Context Gating of Embedded Collective Knowledge for Medical Image Segmentation
These blocks adaptively recalibrate the channel-wise feature responses by utilizing a self-gating mechanism of the global information embedding of the feature maps.
 Ranked #8 on
Lesion Segmentation
on ISIC 2018
Ranked #8 on
Lesion Segmentation
on ISIC 2018
Depth-Based 3D Hand Pose Estimation: From Current Achievements to Future Goals
Official Torch7 implementation of "V2V-PoseNet: Voxel-to-Voxel Prediction Network for Accurate 3D Hand and Human Pose Estimation from a Single Depth Map", CVPR 2018
 Ranked #5 on
Hand Pose Estimation
on HANDS 2017
Ranked #5 on
Hand Pose Estimation
on HANDS 2017


From 2D to 3D Geodesic-based Garment Matching
A new approach for 2D to 3D garment retexturing is proposed based on Gaussian mixture models and thin plate splines (TPS).
ICML 2023 Topological Deep Learning Challenge : Design and Results
This paper presents the computational challenge on topological deep learning that was hosted within the ICML 2023 Workshop on Topology and Geometry in Machine Learning.
Neural Cloth Simulation
Here, we propose the first methodology able to learn realistic cloth dynamics unsupervisedly, and henceforth, a general formulation for neural cloth simulation.
Gate-Shift Networks for Video Action Recognition
Deep 3D CNNs for video action recognition are designed to learn powerful representations in the joint spatio-temporal feature space.
 Ranked #26 on
Action Recognition
on Something-Something V1
(using extra training data)
Ranked #26 on
Action Recognition
on Something-Something V1
(using extra training data)

TopoX: A Suite of Python Packages for Machine Learning on Topological Domains
We introduce TopoX, a Python software suite that provides reliable and user-friendly building blocks for computing and machine learning on topological domains that extend graphs: hypergraphs, simplicial, cellular, path and combinatorial complexes.
Seamless Human Motion Composition with Blended Positional Encodings
Conditional human motion generation is an important topic with many applications in virtual reality, gaming, and robotics.

CrossMoDA 2021 challenge: Benchmark of Cross-Modality Domain Adaptation techniques for Vestibular Schwannoma and Cochlea Segmentation
The aim was to automatically perform unilateral VS and bilateral cochlea segmentation on hrT2 as provided in the testing set (N=137).
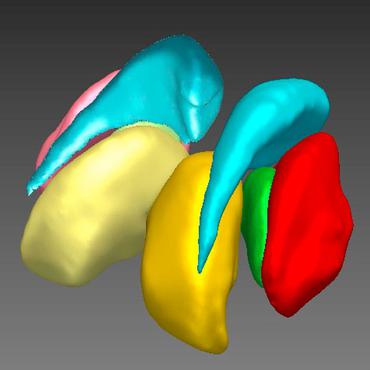

PBNS: Physically Based Neural Simulator for Unsupervised Garment Pose Space Deformation
While deep-based approaches in the domain are becoming a trend, these are data-hungry models.
BeLFusion: Latent Diffusion for Behavior-Driven Human Motion Prediction
To address these issues, we present BeLFusion, a model that, for the first time, leverages latent diffusion models in HMP to sample from a latent space where behavior is disentangled from pose and motion.
 Ranked #1 on
Human Pose Forecasting
on AMASS
(ADE metric)
Ranked #1 on
Human Pose Forecasting
on AMASS
(ADE metric)

SoccerNet 2023 Challenges Results
More information on the tasks, challenges, and leaderboards are available on https://www. soccer-net. org.
SoccerNet 2022 Challenges Results
The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team.
Computing the Testing Error without a Testing Set
Here, we derive an algorithm to estimate the performance gap between training and testing that does not require any testing dataset.


Recurrent CNN for 3D Gaze Estimation using Appearance and Shape Cues
Gaze behavior is an important non-verbal cue in social signal processing and human-computer interaction.
 Ranked #1 on
Gaze Estimation
on EYEDIAP (screen target)
Ranked #1 on
Gaze Estimation
on EYEDIAP (screen target)
Codabench: Flexible, Easy-to-Use and Reproducible Benchmarking Platform
A public instance of Codabench (https://www. codabench. org/) is open to everyone, free of charge, and allows benchmark organizers to compare fairly submissions, under the same setting (software, hardware, data, algorithms), with custom protocols and data formats.
Folded Recurrent Neural Networks for Future Video Prediction
Future video prediction is an ill-posed Computer Vision problem that recently received much attention.
 Ranked #1 on
Video Prediction
on KTH
(Cond metric)
Ranked #1 on
Video Prediction
on KTH
(Cond metric)

LSTA: Long Short-Term Attention for Egocentric Action Recognition
Egocentric activity recognition is one of the most challenging tasks in video analysis.
 Ranked #5 on
Egocentric Activity Recognition
on EGTEA
Ranked #5 on
Egocentric Activity Recognition
on EGTEA
Gloss-free Sign Language Translation: Improving from Visual-Language Pretraining
Many previous methods employ an intermediate representation, i. e., gloss sequences, to facilitate SLT, thus transforming it into a two-stage task of sign language recognition (SLR) followed by sign language translation (SLT).
![]() Ranked #2 on
Gloss-free Sign Language Translation
on PHOENIX14T
Ranked #2 on
Gloss-free Sign Language Translation
on PHOENIX14T
 Gloss-free Sign Language Translation
Gloss-free Sign Language Translation
 Self-Supervised Learning
+3
Self-Supervised Learning
+3
DeePSD: Automatic Deep Skinning And Pose Space Deformation For 3D Garment Animation
We present a novel solution to the garment animation problem through deep learning.
ASTRA: An Action Spotting TRAnsformer for Soccer Videos
In this paper, we introduce ASTRA, a Transformer-based model designed for the task of Action Spotting in soccer matches.
REACT2023: the first Multi-modal Multiple Appropriate Facial Reaction Generation Challenge
The Multi-modal Multiple Appropriate Facial Reaction Generation Challenge (REACT2023) is the first competition event focused on evaluating multimedia processing and machine learning techniques for generating human-appropriate facial reactions in various dyadic interaction scenarios, with all participants competing strictly under the same conditions.
Which Tokens to Use? Investigating Token Reduction in Vision Transformers
While different methods have been explored to achieve this goal, we still lack understanding of the resulting reduction patterns and how those patterns differ across token reduction methods and datasets.

Meta-Album: Multi-domain Meta-Dataset for Few-Shot Image Classification
We introduce Meta-Album, an image classification meta-dataset designed to facilitate few-shot learning, transfer learning, meta-learning, among other tasks.

Survey on Emotional Body Gesture Recognition
Automatic emotion recognition has become a trending research topic in the past decade.
Cultural Vocal Bursts Intensity Prediction
Emotion Recognition
+4
On the effect of age perception biases for real age regression
Our model outperformed a state-of-the-art architecture proposed to separately address apparent and real age regression.

REACT 2024: the Second Multiple Appropriate Facial Reaction Generation Challenge
In dyadic interactions, humans communicate their intentions and state of mind using verbal and non-verbal cues, where multiple different facial reactions might be appropriate in response to a specific speaker behaviour.
Comparison of Spatio-Temporal Models for Human Motion and Pose Forecasting in Face-to-Face Interaction Scenarios
In this work, we present the first systematic comparison of state-of-the-art approaches for behavior forecasting.
Support Vector Machines with Time Series Distance Kernels for Action Classification
Bagheri, Q. Gao, and S. Escalera, "Support Vector Machines with Time Series Distance Kernels for Action Classification", in Proc.

Deep learning with self-supervision and uncertainty regularization to count fish in underwater images
From experiments on both contrasting datasets, we demonstrate our network outperforms the few other deep learning models implemented for solving this task.
Neural Implicit Surfaces for Efficient and Accurate Collisions in Physically Based Simulations
Nonetheless, their memory footprint also grows rapidly and their parallelization in a GPU is problematic due to their branching nature.
Beyond AUROC & co. for evaluating out-of-distribution detection performance
While there has been a growing research interest in developing out-of-distribution (OOD) detection methods, there has been comparably little discussion around how these methods should be evaluated.
Relevance-based Margin for Contrastively-trained Video Retrieval Models
We show that even if we carefully tuned the fixed margin, our technique (which does not have the margin as a hyper-parameter) would still achieve better performance.
 Ranked #7 on
Multi-Instance Retrieval
on EPIC-KITCHENS-100
Ranked #7 on
Multi-Instance Retrieval
on EPIC-KITCHENS-100
Decorrelating neurons using persistence
We propose a novel way to improve the generalisation capacity of deep learning models by reducing high correlations between neurons.
A Generative Multi-Resolution Pyramid and Normal-Conditioning 3D Cloth Draping
RGB cloth generation has been deeply studied in the related literature, however, 3D garment generation remains an open problem.
Gate-Shift-Fuse for Video Action Recognition
3D kernel factorization approaches have been proposed to reduce the complexity of 3D CNNs.
 Ranked #17 on
Action Recognition
on EPIC-KITCHENS-100
(using extra training data)
Ranked #17 on
Action Recognition
on EPIC-KITCHENS-100
(using extra training data)

Sign Language Production: A Review
Sign Language is the dominant yet non-primary form of communication language used in the deaf and hearing-impaired community.

in2IN: Leveraging individual Information to Generate Human INteractions
For this, we introduce in2IN, a novel diffusion model for human-human motion generation which is conditioned not only on the textual description of the overall interaction but also on the individual descriptions of the actions performed by each person involved in the interaction.
RGB-D-based Human Motion Recognition with Deep Learning: A Survey
Specifically, deep learning methods based on the CNN and RNN architectures have been adopted for motion recognition using RGB-D data.
First Impressions: A Survey on Vision-Based Apparent Personality Trait Analysis
However, recently there has been an increasing interest from the computer vision community in analyzing personality from visual data.
Exploiting feature representations through similarity learning, post-ranking and ranking aggregation for person re-identification
In this work, we propose to exploit a post-ranking approach and combine different feature representations through ranking aggregation.

End-to-end Global to Local CNN Learning for Hand Pose Recovery in Depth Data
Despite recent advances in 3D pose estimation of human hands, especially thanks to the advent of CNNs and depth cameras, this task is still far from being solved.

Deep Structure Inference Network for Facial Action Unit Recognition
In recent years, most efforts in automatic AU recognition have been dedicated to learning combinations of local features and to exploiting correlations between Action Units.

Explaining First Impressions: Modeling, Recognizing, and Explaining Apparent Personality from Videos
Explainability and interpretability are two critical aspects of decision support systems.
Automatic Recognition of Facial Displays of Unfelt Emotions
Performance of the proposed model shows that on average it is easier to distinguish among genuine facial expressions of emotion than among unfelt facial expressions of emotion and that certain emotion pairs such as contempt and disgust are more difficult to distinguish than the rest.
WordFence: Text Detection in Natural Images with Border Awareness
In recent years, text recognition has achieved remarkable success in recognizing scanned document text.
End-to-end semantic face segmentation with conditional random fields as convolutional, recurrent and adversarial networks
Recent years have seen a sharp increase in the number of related yet distinct advances in semantic segmentation.
ChaLearn Looking at People: A Review of Events and Resources
This paper reviews associated events, and introduces the ChaLearn LAP platform where public resources (including code, data and preprints of papers) related to the organized events are available.
Survey on RGB, 3D, Thermal, and Multimodal Approaches for Facial Expression Recognition: History, Trends, and Affect-related Applications
Facial expressions are an important way through which humans interact socially.

Error-Correcting Factorization
To address these limitations this paper proposes an Error-Correcting Factorization (ECF) method, our contribution is three fold: (I) We propose a novel representation of the error-correction capability, called the design matrix, that enables us to build an ECOC on the basis of allocating correction to pairs of classes.
Non-Verbal Communication Analysis in Victim-Offender Mediations
In this paper we present a non-invasive ambient intelligence framework for the semi-automatic analysis of non-verbal communication applied to the restorative justice field.
A Gesture Recognition System for Detecting Behavioral Patterns of ADHD
We propose an extension of DTW using one-class classifiers in order to be able to encode the variability of a gesture category, and thus, perform an alignment between a gesture sample and a gesture class.
Beyond One-hot Encoding: lower dimensional target embedding
Following this observation, we embed the targets into a low-dimensional space, drastically improving convergence speed while preserving accuracy.
SMPLR: Deep SMPL reverse for 3D human pose and shape recovery
By implementing SMPLR as an encoder-decoder we avoid the need of complex constraints on pose and shape.
Multi-task human analysis in still images: 2D/3D pose, depth map, and multi-part segmentation
In this work, we analyze four related human analysis tasks in still images in a multi-task scenario by leveraging such datasets.
Hierarchical Feature Aggregation Networks for Video Action Recognition
Most action recognition methods base on a) a late aggregation of frame level CNN features using average pooling, max pooling, or RNN, among others, or b) spatio-temporal aggregation via 3D convolutions.
 Ranked #51 on
Action Recognition
on HMDB-51
(using extra training data)
Ranked #51 on
Action Recognition
on HMDB-51
(using extra training data)
FBK-HUPBA Submission to the EPIC-Kitchens 2019 Action Recognition Challenge
In this report we describe the technical details of our submission to the EPIC-Kitchens 2019 action recognition challenge.
ChaLearn Looking at People: IsoGD and ConGD Large-scale RGB-D Gesture Recognition
The ChaLearn large-scale gesture recognition challenge has been run twice in two workshops in conjunction with the International Conference on Pattern Recognition (ICPR) 2016 and International Conference on Computer Vision (ICCV) 2017, attracting more than $200$ teams round the world.
CASIA-SURF: A Large-scale Multi-modal Benchmark for Face Anti-spoofing
To facilitate face anti-spoofing research, we introduce a large-scale multi-modal dataset, namely CASIA-SURF, which is the largest publicly available dataset for face anti-spoofing in terms of both subjects and modalities.
On the Effect of Observed Subject Biases in Apparent Personality Analysis from Audio-visual Signals
Furthermore, given the interpretability nature of our network design, we provide an incremental analysis on the impact of each possible source of bias on final network predictions.
Static and Dynamic Fusion for Multi-modal Cross-ethnicity Face Anti-spoofing
Regardless of the usage of deep learning and handcrafted methods, the dynamic information from videos and the effect of cross-ethnicity are rarely considered in face anti-spoofing.
CASIA-SURF CeFA: A Benchmark for Multi-modal Cross-ethnicity Face Anti-spoofing
Ethnic bias has proven to negatively affect the performance of face recognition systems, and it remains an open research problem in face anti-spoofing.
Cross-ethnicity Face Anti-spoofing Recognition Challenge: A Review
Although ethnic bias has been verified to severely affect the performance of face recognition systems, it still remains an open research problem in face anti-spoofing.
FBK-HUPBA Submission to the EPIC-Kitchens Action Recognition 2020 Challenge
In this report we describe the technical details of our submission to the EPIC-Kitchens Action Recognition 2020 Challenge.
ChaLearn Looking at People and Faces of the World: Face Analysis Workshop and Challenge 2016
A custom-build application was used to collect and label data about the apparent age of people (as opposed to the real age).
 Ranked #2 on
Gender Prediction
on FotW Gender
Ranked #2 on
Gender Prediction
on FotW Gender
FairFace Challenge at ECCV 2020: Analyzing Bias in Face Recognition
This work summarizes the 2020 ChaLearn Looking at People Fair Face Recognition and Analysis Challenge and provides a description of the top-winning solutions and analysis of the results.

Person Perception Biases Exposed: Revisiting the First Impressions Dataset
This work revisits the ChaLearn First Impressions database, annotated for personality perception using pairwise comparisons via crowdsourcing.
Context-Aware Personality Inference in Dyadic Scenarios: Introducing the UDIVA Dataset
This paper introduces UDIVA, a new non-acted dataset of face-to-face dyadic interactions, where interlocutors perform competitive and collaborative tasks with different behavior elicitation and cognitive workload.
Learning to Recognize Actions on Objects in Egocentric Video with Attention Dictionaries
We present EgoACO, a deep neural architecture for video action recognition that learns to pool action-context-object descriptors from frame level features by leveraging the verb-noun structure of action labels in egocentric video datasets.
Contrastive Context-Aware Learning for 3D High-Fidelity Mask Face Presentation Attack Detection
To bridge the gap to real-world applications, we introduce a largescale High-Fidelity Mask dataset, namely CASIA-SURF HiFiMask (briefly HiFiMask).
ChaLearn LAP Large Scale Signer Independent Isolated Sign Language Recognition Challenge: Design, Results and Future Research
However, several open challenges still need to be solved to allow SLR to be useful in practice.
Deep unsupervised 3D human body reconstruction from a sparse set of landmarks
In this paper we propose the first deep unsupervised approach in human body reconstruction to estimate body surface from a sparse set of landmarks, so called DeepMurf.
ChaLearn Looking at People: Inpainting and Denoising challenges
Dealing with incomplete information is a well studied problem in the context of machine learning and computational intelligence.

3D High-Fidelity Mask Face Presentation Attack Detection Challenge
The threat of 3D masks to face recognition systems is increasingly serious and has been widely concerned by researchers.
ZS-SLR: Zero-Shot Sign Language Recognition from RGB-D Videos
To benefit from the vision Transformer capabilities, we use two vision Transformer models, for human detection and visual features representation.
Multi-Modal Zero-Shot Sign Language Recognition
Zero-Shot Learning (ZSL) has rapidly advanced in recent years.
Dyadformer: A Multi-modal Transformer for Long-Range Modeling of Dyadic Interactions
Personality computing has become an emerging topic in computer vision, due to the wide range of applications it can be used for.

SAIC_Cambridge-HuPBA-FBK Submission to the EPIC-Kitchens-100 Action Recognition Challenge 2021
This report presents the technical details of our submission to the EPIC-Kitchens-100 Action Recognition Challenge 2021.
Multi-Task Classification of Sewer Pipe Defects and Properties using a Cross-Task Graph Neural Network Decoder
In order to efficiently manage the sewerage infrastructure, automated sewer inspection has to be utilized.
All You Need In Sign Language Production
To make an easy and mutual communication between the hearing-impaired and the hearing communities, building a robust system capable of translating the spoken language into sign language and vice versa is fundamental.
Cultural Vocal Bursts Intensity Prediction
Sign Language Production
+2
MyoPS: A Benchmark of Myocardial Pathology Segmentation Combining Three-Sequence Cardiac Magnetic Resonance Images
Assessment of myocardial viability is essential in diagnosis and treatment management of patients suffering from myocardial infarction, and classification of pathology on myocardium is the key to this assessment.
Winning solutions and post-challenge analyses of the ChaLearn AutoDL challenge 2019
Code submissions were executed on hidden tasks, with limited time and computational resources, pushing solutions that get results quickly.

Video Transformers: A Survey
Transformer models have shown great success handling long-range interactions, making them a promising tool for modeling video.
Didn't see that coming: a survey on non-verbal social human behavior forecasting
Non-verbal social human behavior forecasting has increasingly attracted the interest of the research community in recent years.
Towards Self-Supervised Gaze Estimation
Recent joint embedding-based self-supervised methods have surpassed standard supervised approaches on various image recognition tasks such as image classification.

Predicting the generalization gap in neural networks using topological data analysis
Understanding how neural networks generalize on unseen data is crucial for designing more robust and reliable models.
Word separation in continuous sign language using isolated signs and post-processing
Results of the continuous sign videos confirm the efficiency of the proposed model to deal with isolated sign boundaries detection.
UniUD-FBK-UB-UniBZ Submission to the EPIC-Kitchens-100 Multi-Instance Retrieval Challenge 2022
This report presents the technical details of our submission to the EPIC-Kitchens-100 Multi-Instance Retrieval Challenge 2022.
Ranked #3 on
Multi-Instance Retrieval
on EPIC-KITCHENS-100
Analysis of the AutoML Challenge Series 2015–2018
The solutions of the winners are systematically benchmarked over all datasets of all rounds and compared with canonical machine learning algorithms available in scikit-learn.
 Ranked #1 on
AutoML
on Chalearn-AutoML-1
Ranked #1 on
AutoML
on Chalearn-AutoML-1
A Non-Anatomical Graph Structure for isolated hand gesture separation in continuous gesture sequences
Recently, one model has been presented to deal with the challenge of the boundary detection of isolated gestures in a continuous gesture video [17].
NeurIPS'22 Cross-Domain MetaDL competition: Design and baseline results
We present the design and baseline results for a new challenge in the ChaLearn meta-learning series, accepted at NeurIPS'22, focusing on "cross-domain" meta-learning.
Biomedical image analysis competitions: The state of current participation practice
Of these, 84% were based on standard architectures.
Surveillance Face Anti-spoofing
In order to promote relevant research and fill this gap in the community, we collect a large-scale Surveillance High-Fidelity Mask (SuHiFiMask) dataset captured under 40 surveillance scenes, which has 101 subjects from different age groups with 232 3D attacks (high-fidelity masks), 200 2D attacks (posters, portraits, and screens), and 2 adversarial attacks.

Blowing in the Wind: CycleNet for Human Cinemagraphs from Still Images
We investigate the problem in the context of dressed humans under the wind.
Surveillance Face Presentation Attack Detection Challenge
Based on this dataset and protocol-$3$ for evaluating the robustness of the algorithm under quality changes, we organized a face presentation attack detection challenge in surveillance scenarios.
Exploring Emotion Expression Recognition in Older Adults Interacting with a Virtual Coach
The EMPATHIC project aimed to design an emotionally expressive virtual coach capable of engaging healthy seniors to improve well-being and promote independent aging.
Topological Data Analysis for Neural Network Analysis: A Comprehensive Survey
We discuss different strategies to obtain topological information from data and neural networks by means of TDA.
SADA: Semantic adversarial unsupervised domain adaptation for Temporal Action Localization
Temporal Action Localization (TAL) is a complex task that poses relevant challenges, particularly when attempting to generalize on new -- unseen -- domains in real-world applications.

Cr-net: A deep classification-regression network for multimodal apparent personality analysis
First impressions strongly influence social interactions, having a high impact in the personal and professional life.

Unified Physical-Digital Face Attack Detection
These three modules seamlessly form a robust unified attack detection framework.

A Transformer Model for Boundary Detection in Continuous Sign Language
One of the prominent challenges in CSLR pertains to accurately detecting the boundaries of isolated signs within a continuous video stream.
CFPL-FAS: Class Free Prompt Learning for Generalizable Face Anti-spoofing
Specifically, we propose a novel Class Free Prompt Learning (CFPL) paradigm for DG FAS, which utilizes two lightweight transformers, namely Content Q-Former (CQF) and Style Q-Former (SQF), to learn the different semantic prompts conditioned on content and style features by using a set of learnable query vectors, respectively.
Your Image is My Video: Reshaping the Receptive Field via Image-To-Video Differentiable AutoAugmentation and Fusion
The landscape of deep learning research is moving towards innovative strategies to harness the true potential of data.
A noisy elephant in the room: Is your out-of-distribution detector robust to label noise?
The ability to detect unfamiliar or unexpected images is essential for safe deployment of computer vision systems.
T-DEED: Temporal-Discriminability Enhancer Encoder-Decoder for Precise Event Spotting in Sports Videos
In this paper, we introduce T-DEED, a Temporal-Discriminability Enhancer Encoder-Decoder for Precise Event Spotting in sports videos.
Unified Physical-Digital Attack Detection Challenge
Based on this dataset, we organized a Unified Physical-Digital Face Attack Detection Challenge to boost the research in Unified Attack Detections.
AI Competitions and Benchmarks: Dataset Development
Initially, we develop the tasks involved in dataset development and offer insights into their effective management (including requirements, design, implementation, evaluation, distribution, and maintenance).
