Search Results for author:
Found 58 papers, 28 papers with code
Expectation-Maximization Attention Networks for Semantic Segmentation
It is designed to compute the representation of each position by a weighted sum of the features at all positions.
 Ranked #11 on
Semantic Segmentation
on COCO-Stuff test
Ranked #11 on
Semantic Segmentation
on COCO-Stuff test

Improving Semantic Segmentation via Decoupled Body and Edge Supervision
Our insight is that appealing performance of semantic segmentation requires \textit{explicitly} modeling the object \textit{body} and \textit{edge}, which correspond to the high and low frequency of the image.

Towards Open Vocabulary Learning: A Survey
To our knowledge, this is the first comprehensive literature review of open vocabulary learning.
Mask Transfiner for High-Quality Instance Segmentation
Instead of operating on regular dense tensors, our Mask Transfiner decomposes and represents the image regions as a quadtree.
 Ranked #1 on
Instance Segmentation
on BDD100K val
Ranked #1 on
Instance Segmentation
on BDD100K val

Quasi-Dense Similarity Learning for Multiple Object Tracking
Compared to methods with similar detectors, it boosts almost 10 points of MOTA and significantly decreases the number of ID switches on BDD100K and Waymo datasets.
 Ranked #1 on
One-Shot Object Detection
on PASCAL VOC 2012 val
Ranked #1 on
One-Shot Object Detection
on PASCAL VOC 2012 val


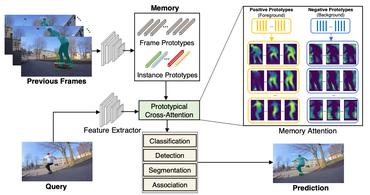
Prototypical Cross-Attention Networks for Multiple Object Tracking and Segmentation
We propose Prototypical Cross-Attention Network (PCAN), capable of leveraging rich spatio-temporal information for online multiple object tracking and segmentation.
 Ranked #1 on
Video Instance Segmentation
on BDD100K val
Ranked #1 on
Video Instance Segmentation
on BDD100K val
 Multi-Object Tracking and Segmentation
Multi-Object Tracking and Segmentation
 Multiple Object Track and Segmentation
+3
Multiple Object Track and Segmentation
+3
Towards Efficient Scene Understanding via Squeeze Reasoning
Instead of propagating information on the spatial map, we first learn to squeeze the input feature into a channel-wise global vector and perform reasoning within the single vector where the computation cost can be significantly reduced.
Is Attention Better Than Matrix Decomposition?
As an essential ingredient of modern deep learning, attention mechanism, especially self-attention, plays a vital role in the global correlation discovery.
 Ranked #7 on
Semantic Segmentation
on PASCAL VOC 2012 test
Ranked #7 on
Semantic Segmentation
on PASCAL VOC 2012 test

Co-Evolution of Pose and Mesh for 3D Human Body Estimation from Video
Despite significant progress in single image-based 3D human mesh recovery, accurately and smoothly recovering 3D human motion from a video remains challenging.

PointFlow: Flowing Semantics Through Points for Aerial Image Segmentation
Experimental results on three different aerial segmentation datasets suggest that the proposed method is more effective and efficient than state-of-the-art general semantic segmentation methods.
SOGNet: Scene Overlap Graph Network for Panoptic Segmentation
In order to overcome the lack of supervision, we introduce a differentiable module to resolve the overlap between any pair of instances.
 Ranked #8 on
Panoptic Segmentation
on Cityscapes test
Ranked #8 on
Panoptic Segmentation
on Cityscapes test

Explore In-Context Learning for 3D Point Cloud Understanding
With the rise of large-scale models trained on broad data, in-context learning has become a new learning paradigm that has demonstrated significant potential in natural language processing and computer vision tasks.
Interweaved Graph and Attention Network for 3D Human Pose Estimation
Despite substantial progress in 3D human pose estimation from a single-view image, prior works rarely explore global and local correlations, leading to insufficient learning of human skeleton representations.
Betrayed by Captions: Joint Caption Grounding and Generation for Open Vocabulary Instance Segmentation
Experiments on the COCO dataset with two settings: Open Vocabulary Instance Segmentation (OVIS) and Open Set Panoptic Segmentation (OSPS) demonstrate the superiority of the CGG.
Skeleton-in-Context: Unified Skeleton Sequence Modeling with In-Context Learning
Under this setting, the model can perceive tasks from prompts and accomplish them without any extra task-specific head predictions or model fine-tuning.
GATOR: Graph-Aware Transformer with Motion-Disentangled Regression for Human Mesh Recovery from a 2D Pose
3D human mesh recovery from a 2D pose plays an important role in various applications.
 Ranked #146 on
3D Human Pose Estimation
on Human3.6M
Ranked #146 on
3D Human Pose Estimation
on Human3.6M
Self-Refining Deep Symmetry Enhanced Network for Rain Removal
Rain removal aims to extract and remove rain streaks from images.
Bi-directional Exponential Angular Triplet Loss for RGB-Infrared Person Re-Identification
As an angularly discriminative feature space is important for classifying the human images based on their embedding vectors, in this paper, we propose a novel ranking loss function, named Bi-directional Exponential Angular Triplet Loss, to help learn an angularly separable common feature space by explicitly constraining the included angles between embedding vectors.

MD-Dose: A Diffusion Model based on the Mamba for Radiotherapy Dose Prediction
To tackle these challenges, we introduce a novel diffusion model, MD-Dose, based on the Mamba architecture for predicting radiation therapy dose distribution in thoracic cancer patients.

SWAFN: Sentimental Words Aware Fusion Network for Multimodal Sentiment Analysis
For the aggregation part, we design a multitask of sentimental words classification to help and guide the deep fusion of the three modalities and obtain the final sentimental words aware fusion representation.

Temporal Pyramid Network for Pedestrian Trajectory Prediction with Multi-Supervision
Predicting human motion behavior in a crowd is important for many applications, ranging from the natural navigation of autonomous vehicles to intelligent security systems of video surveillance.
 Ranked #15 on
Trajectory Prediction
on ETH/UCY
Ranked #15 on
Trajectory Prediction
on ETH/UCY

Towards Robust Referring Image Segmentation
It considers the negative sentence inputs besides the regular positive text inputs.
Neural Clustering based Visual Representation Learning
In this work, we propose feature extraction with clustering (FEC), a conceptually elegant yet surprisingly ad-hoc interpretable neural clustering framework, which views feature extraction as a process of selecting representatives from data and thus automatically captures the underlying data distribution.


ModelNet-O: A Large-Scale Synthetic Dataset for Occlusion-Aware Point Cloud Classification
Through extensive experiments, we demonstrate that our PointMLS achieves state-of-the-art results on ModelNet-O and competitive results on regular datasets, and it is robust and effective.

Kernalised Multi-resolution Convnet for Visual Tracking
Visual tracking is intrinsically a temporal problem.
PI-Trans: Parallel-ConvMLP and Implicit-Transformation Based GAN for Cross-View Image Translation
For semantic-guided cross-view image translation, it is crucial to learn where to sample pixels from the source view image and where to reallocate them guided by the target view semantic map, especially when there is little overlap or drastic view difference between the source and target images.
Calibration-based Dual Prototypical Contrastive Learning Approach for Domain Generalization Semantic Segmentation
Based on these observations, a calibration-based dual prototypical contrastive learning (CDPCL) approach is proposed to reduce the domain discrepancy between the learned class-wise features and the prototypes of different domains for domain generalization semantic segmentation.
VG4D: Vision-Language Model Goes 4D Video Recognition
By transferring the knowledge of the VLM to the 4D encoder and combining the VLM, our VG4D achieves improved recognition performance.


Compression of phase-only holograms with JPEG standard and deep learning
It is a critical issue to reduce the enormous amount of data in the processing, storage and transmission of a hologram in digital format.
Review on Optical Image Hiding and Watermarking Techniques
Information security is a critical issue in modern society and image watermarking can effectively prevent unauthorized information access.
Sensing Urban Land-Use Patterns By Integrating Google Tensorflow And Scene-Classification Models
To take advantage of the deep-learning method in detecting urban land-use patterns, we applied a transfer-learning-based remote-sensing image approach to extract and classify features.

Recurrent Squeeze-and-Excitation Context Aggregation Net for Single Image Deraining
In heavy rain, rain streaks have various directions and shapes, which can be regarded as the accumulation of multiple rain streak layers.
 Ranked #7 on
Single Image Deraining
on Test2800
Ranked #7 on
Single Image Deraining
on Test2800

Primitive-based 3D Building Modeling, Sensor Simulation, and Estimation
As we begin to consider modeling large, realistic 3D building scenes, it becomes necessary to consider a more compact representation over the polygonal mesh model.
Masked Non-Autoregressive Image Captioning
Existing captioning models often adopt the encoder-decoder architecture, where the decoder uses autoregressive decoding to generate captions, such that each token is generated sequentially given the preceding generated tokens.


Quality Assessment of DIBR-synthesized views: An Overview
In this paper, we provide a comprehensive survey on various current approaches for DIBR-synthesized views.
Dynamical System Inspired Adaptive Time Stepping Controller for Residual Network Families
We establish a stability condition for ResNets with step sizes and weight parameters, and point out the effects of step sizes on the stability and performance.
Spatial Pyramid Based Graph Reasoning for Semantic Segmentation
The convolution operation suffers from a limited receptive filed, while global modeling is fundamental to dense prediction tasks, such as semantic segmentation.
COVID-19 Literature Topic-Based Search via Hierarchical NMF
A dataset of COVID-19-related scientific literature is compiled, combining the articles from several online libraries and selecting those with open access and full text available.
Who killed Lilly Kane? A case study in applying knowledge graphs to crime fiction
We present a preliminary study of a knowledge graph created from season one of the television show Veronica Mars, which follows the eponymous young private investigator as she attempts to solve the murder of her best friend Lilly Kane.
Optimization Induced Equilibrium Networks
In this paper, we investigate an emerging question: can an implicit equilibrium model's equilibrium point be regarded as the solution of an optimization problem?
POI-Transformers: POI Entity Matching through POI Embeddings by Incorporating Semantic and Geographic Information
A general and robust POI embedding framework, the POI-Transformers, is initially proposed in this study to address these problems of POI entity matching.
Data Augmentation of Incorporating Real Error Patterns and Linguistic Knowledge for Grammatical Error Correction
Moreover, we also find that linguistic knowledge can be incorporated into data augmentation for generating more representative and more diverse synthetic data.


Multimodal Sentiment Analysis with Multi-perspective Fusion Network Focusing on Sense Attentive Language
Different from previous studies, we use the language modality as the main part of the final joint representation, and propose a multi-stage and uni-stage fusion strategy to get the fusion representation of the multiple modalities to assist the final language-dominated multimodal representation.
Deep Convolution Network Based Emotion Analysis for Automatic Detection of Mild Cognitive Impairment in the Elderly
With this dataset, the proposed system has successfully achieved the detection accuracy of 73. 3%.
Distributed randomized Kaczmarz for the adversarial workers
Developing large-scale distributed methods that are robust to the presence of adversarial or corrupted workers is an important part of making such methods practical for real-world problems.
STGlow: A Flow-based Generative Framework with Dual Graphormer for Pedestrian Trajectory Prediction
Different from previous approaches, our method can more precisely model the underlying data distribution by optimizing the exact log-likelihood of motion behaviors.

Randomized Kaczmarz in Adversarial Distributed Setting
Additionally, the efficiency of the proposed methods for solving convex problems is shown in simulations with the presence of adversaries.
Unsupervised Self-Driving Attention Prediction via Uncertainty Mining and Knowledge Embedding
Predicting attention regions of interest is an important yet challenging task for self-driving systems.
SGFormer: Semantic Graph Transformer for Point Cloud-based 3D Scene Graph Generation
In this paper, we propose a novel model called SGFormer, Semantic Graph TransFormer for point cloud-based 3D scene graph generation.

A Memory-Augmented Multi-Task Collaborative Framework for Unsupervised Traffic Accident Detection in Driving Videos
Different from previous approaches, our method can more accurately detect both ego-involved and non-ego accidents by simultaneously modeling appearance changes and object motions in video frames through the collaboration of optical flow reconstruction and future object localization tasks.
Energy-Guided Diffusion Model for CBCT-to-CT Synthesis
Cone Beam CT (CBCT) plays a crucial role in Adaptive Radiation Therapy (ART) by accurately providing radiation treatment when organ anatomy changes occur.
Image Copy-Move Forgery Detection via Deep Cross-Scale PatchMatch
The recently developed deep algorithms achieve promising progress in the field of image copy-move forgery detection (CMFD).
Multi-scale Target-Aware Framework for Constrained Image Splicing Detection and Localization
Additionally, in order to handle scale transformations, we introduce a multi-scale projection method, which can be readily integrated into our target-aware framework that enables the attention process to be conducted between tokens containing information of varying scales.
FedLPA: Personalized One-shot Federated Learning with Layer-Wise Posterior Aggregation
Efficiently aggregating trained neural networks from local clients into a global model on a server is a widely researched topic in federated learning.
SP-DiffDose: A Conditional Diffusion Model for Radiation Dose Prediction Based on Multi-Scale Fusion of Anatomical Structures, Guided by SwinTransformer and Projector
To address these limitations, we propose a dose prediction diffusion model based on SwinTransformer and a projector, SP-DiffDose.
Text-Driven Traffic Anomaly Detection with Temporal High-Frequency Modeling in Driving Videos
Traffic anomaly detection (TAD) in driving videos is critical for ensuring the safety of autonomous driving and advanced driver assistance systems.
Uncertainty-Aware Testing-Time Optimization for 3D Human Pose Estimation
We observe that previous optimization-based methods commonly rely on projection constraint, which only ensures alignment in 2D space, potentially leading to the overfitting problem.
Neural Graphics Primitives-based Deformable Image Registration for On-the-fly Motion Extraction
Intra-fraction motion in radiotherapy is commonly modeled using deformable image registration (DIR).

