Search Results for author:
Found 159 papers, 85 papers with code
The SkatingVerse Workshop & Challenge: Methods and Results
The SkatingVerse Workshop & Challenge aims to encourage research in developing novel and accurate methods for human action understanding.
DiffGen: Robot Demonstration Generation via Differentiable Physics Simulation, Differentiable Rendering, and Vision-Language Model
In this paper, we propose DiffGen, a novel framework that integrates differentiable physics simulation, differentiable rendering, and a vision-language model to enable automatic and efficient generation of robot demonstrations.

MS-MANO: Enabling Hand Pose Tracking with Biomechanical Constraints
To address this, we integrate a musculoskeletal system with a learnable parametric hand model, MANO, to create a new model, MS-MANO.

SemGrasp: Semantic Grasp Generation via Language Aligned Discretization
We introduce a discrete representation that aligns the grasp space with semantic space, enabling the generation of grasp postures in accordance with language instructions.
OAKINK2: A Dataset of Bimanual Hands-Object Manipulation in Complex Task Completion
Based on the 3-level abstraction of OAKINK2, we explore a task-oriented framework for Complex Task Completion (CTC).

RH20T-P: A Primitive-Level Robotic Dataset Towards Composable Generalization Agents
The ultimate goals of robotic learning is to acquire a comprehensive and generalizable robotic system capable of performing both seen skills within the training distribution and unseen skills in novel environments.

RPMArt: Towards Robust Perception and Manipulation for Articulated Objects
Our primary contribution is a Robust Articulation Network (RoArtNet) that is able to predict both joint parameters and affordable points robustly by local feature learning and point tuple voting.
GLC++: Source-Free Universal Domain Adaptation through Global-Local Clustering and Contrastive Affinity Learning
GLC++ enhances the novel category clustering accuracy of GLC by 4. 3% in open-set scenarios on Office-Home.


ManiPose: A Comprehensive Benchmark for Pose-aware Object Manipulation in Robotics
Robotic manipulation in everyday scenarios, especially in unstructured environments, requires skills in pose-aware object manipulation (POM), which adapts robots' grasping and handling according to an object's 6D pose.

ShapeBoost: Boosting Human Shape Estimation with Part-Based Parameterization and Clothing-Preserving Augmentation
Accurate human shape recovery from a monocular RGB image is a challenging task because humans come in different shapes and sizes and wear different clothes.

EmbodiedScan: A Holistic Multi-Modal 3D Perception Suite Towards Embodied AI
In the realm of computer vision and robotics, embodied agents are expected to explore their environment and carry out human instructions.
PACE: A Large-Scale Dataset with Pose Annotations in Cluttered Environments
We introduce PACE (Pose Annotations in Cluttered Environments), a large-scale benchmark designed to advance the development and evaluation of pose estimation methods in cluttered scenarios.
Primitive-based 3D Human-Object Interaction Modelling and Programming
To explore an effective embedding of HAOI for the machine, we build a new benchmark on 3D HAOI consisting of primitives together with their images and propose a task requiring machines to recover 3D HAOI using primitives from images.

Revisit Human-Scene Interaction via Space Occupancy
Human-scene Interaction (HSI) generation is a challenging task and crucial for various downstream tasks.
Dancing with Still Images: Video Distillation via Static-Dynamic Disentanglement
It first distills the videos into still images as static memory and then compensates the dynamic and motion information with a learnable dynamic memory block.
Symbol-LLM: Leverage Language Models for Symbolic System in Visual Human Activity Reasoning
One possible path of activity reasoning is building a symbolic system composed of symbols and rules, where one rule connects multiple symbols, implying human knowledge and reasoning abilities.
RFTrans: Leveraging Refractive Flow of Transparent Objects for Surface Normal Estimation and Manipulation
By leveraging refractive flow as an intermediate representation, the proposed method circumvents the drawbacks of directly predicting the geometry (e. g. surface normal) from images and helps bridge the sim-to-real gap.
UniFolding: Towards Sample-efficient, Scalable, and Generalizable Robotic Garment Folding
Training data is collected via a human-centric process with offline and online stages.
Bridging the Gap between Human Motion and Action Semantics via Kinematic Phrases
The goal of motion understanding is to establish a reliable mapping between motion and action semantics, while it is a challenging many-to-many problem.
GAMMA: Generalizable Articulation Modeling and Manipulation for Articulated Objects
Results show that GAMMA significantly outperforms SOTA articulation modeling and manipulation algorithms in unseen and cross-category articulated objects.
EgoPCA: A New Framework for Egocentric Hand-Object Interaction Understanding
With the surge in attention to Egocentric Hand-Object Interaction (Ego-HOI), large-scale datasets such as Ego4D and EPIC-KITCHENS have been proposed.


CHORD: Category-level Hand-held Object Reconstruction via Shape Deformation
This can be attributed to the fact that humans have mastered the shape prior of the 'mug' category, and can quickly establish the corresponding relations between different mug instances and the prior, such as where the rim and handle are located.
ClothesNet: An Information-Rich 3D Garment Model Repository with Simulated Clothes Environment
We present ClothesNet: a large-scale dataset of 3D clothes objects with information-rich annotations.

Color-NeuS: Reconstructing Neural Implicit Surfaces with Color
Mesh is extracted from the signed distance function (SDF) network for the surface, and color for each surface vertex is drawn from the global color network.
RH20T: A Comprehensive Robotic Dataset for Learning Diverse Skills in One-Shot
A key challenge in robotic manipulation in open domains is how to acquire diverse and generalizable skills for robots.
Distill Gold from Massive Ores: Efficient Dataset Distillation via Critical Samples Selection
Our method consistently enhances the distillation algorithms, even on much larger-scale and more heterogeneous datasets, e. g. ImageNet-1K and Kinetics-400.
NIKI: Neural Inverse Kinematics with Invertible Neural Networks for 3D Human Pose and Shape Estimation
In this work, we present NIKI (Neural Inverse Kinematics with Invertible Neural Network), which models bi-directional errors to improve the robustness to occlusions and obtain pixel-aligned accuracy.
 Ranked #1 on
3D Human Pose Estimation
on AGORA
Ranked #1 on
3D Human Pose Estimation
on AGORA
HybrIK-X: Hybrid Analytical-Neural Inverse Kinematics for Whole-body Mesh Recovery
To address these issues, this paper presents a novel hybrid inverse kinematics solution, HybrIK, that integrates the merits of 3D keypoint estimation and body mesh recovery in a unified framework.
 Ranked #1 on
3D Human Reconstruction
on AGORA
Ranked #1 on
3D Human Reconstruction
on AGORA

POEM: Reconstructing Hand in a Point Embedded Multi-view Stereo
Enable neural networks to capture 3D geometrical-aware features is essential in multi-view based vision tasks.
From Isolated Islands to Pangea: Unifying Semantic Space for Human Action Understanding
By aligning the classes of previous datasets to our semantic space, we gather (image/video/skeleton/MoCap) datasets into a unified database in a unified label system, i. e., bridging "isolated islands" into a "Pangea".

Visual-Tactile Sensing for In-Hand Object Reconstruction
We propose a simulation environment, VT-Sim, which supports generating hand-object interaction for both rigid and deformable objects.
GarmentTracking: Category-Level Garment Pose Tracking
In this work, we present a complete package to address the category-level garment pose tracking task: (1) A recording system VR-Garment, with which users can manipulate virtual garment models in simulation through a VR interface.
Upcycling Models under Domain and Category Shift
We examine the superiority of our GLC on multiple benchmarks with different category shift scenarios, including partial-set, open-set, and open-partial-set DA.
 Ranked #2 on
Universal Domain Adaptation
on VisDA2017
Ranked #2 on
Universal Domain Adaptation
on VisDA2017
CRIN: Rotation-Invariant Point Cloud Analysis and Rotation Estimation via Centrifugal Reference Frame
CRIN directly takes the coordinates of points as input and transforms local points into rotation-invariant representations via centrifugal reference frames.
Target-Referenced Reactive Grasping for Dynamic Objects
Reactive grasping, which enables the robot to successfully grasp dynamic moving objects, is of great interest in robotics.
Stimulus Verification Is a Universal and Effective Sampler in Multi-Modal Human Trajectory Prediction
To comprehensively cover the uncertainty of the future, the common practice of multi-modal human trajectory prediction is to first generate a set/distribution of candidate future trajectories and then sample required numbers of trajectories from them as final predictions.
ClothPose: A Real-world Benchmark for Visual Analysis of Garment Pose via An Indirect Recording Solution
In this work, we propose a recording system, GarmentTwin, which can track garment poses in dynamic settings such as manipulation.
Unsupervised 3D Point Cloud Representation Learning by Triangle Constrained Contrast for Autonomous Driving
In this paper, we design the Triangle Constrained Contrast (TriCC) framework tailored for autonomous driving scenes which learns 3D unsupervised representations through both the multimodal information and dynamic of temporal sequences.


Beyond Object Recognition: A New Benchmark towards Object Concept Learning
To support OCL, we build a densely annotated knowledge base including extensive labels for three levels of object concept (category, attribute, affordance), and the causal relations of three levels.
One-Shot General Object Localization
In contrast, our proposed OneLoc algorithm efficiently finds the object center and bounding box size by a special voting scheme.
CPPF++: Uncertainty-Aware Sim2Real Object Pose Estimation by Vote Aggregation
We introduce a novel method, CPPF++, designed for sim-to-real pose estimation.
Discovering A Variety of Objects in Spatio-Temporal Human-Object Interactions
In daily HOIs, humans often interact with a variety of objects, e. g., holding and touching dozens of household items in cleaning.
AlphaPose: Whole-Body Regional Multi-Person Pose Estimation and Tracking in Real-Time
Accurate whole-body multi-person pose estimation and tracking is an important yet challenging topic in computer vision.

SAM-RL: Sensing-Aware Model-Based Reinforcement Learning via Differentiable Physics-Based Simulation and Rendering
Model-based reinforcement learning (MBRL) is recognized with the potential to be significantly more sample-efficient than model-free RL.
 Deformable Object Manipulation
Deformable Object Manipulation
 Model-based Reinforcement Learning
+2
Model-based Reinforcement Learning
+2
Neural Eigenfunctions Are Structured Representation Learners
Unlike prior spectral methods such as Laplacian Eigenmap that operate in a nonparametric manner, Neural Eigenmap leverages NeuralEF to parametrically model eigenfunctions using a neural network.
DART: Articulated Hand Model with Diverse Accessories and Rich Textures
Unity GUI is also provided to generate synthetic hand data with user-defined settings, e. g., pose, camera, background, lighting, textures, and accessories.

X-NeRF: Explicit Neural Radiance Field for Multi-Scene 360$^{\circ} $ Insufficient RGB-D Views
In this paper, we focus on a rarely discussed but important setting: can we train one model that can represent multiple scenes, with 360$^\circ $ insufficient views and RGB-D images?

D&D: Learning Human Dynamics from Dynamic Camera
In this work, we present D&D (Learning Human Dynamics from Dynamic Camera), which leverages the laws of physics to reconstruct 3D human motion from the in-the-wild videos with a moving camera.
Constructing Balance from Imbalance for Long-tailed Image Recognition
Previous methods tackle with data imbalance from the viewpoints of data distribution, feature space, and model design, etc.
Mining Cross-Person Cues for Body-Part Interactiveness Learning in HOI Detection
Though significant progress has been made, interactiveness learning remains a challenging problem in HOI detection: existing methods usually generate redundant negative H-O pair proposals and fail to effectively extract interactive pairs.
 Ranked #9 on
Human-Object Interaction Detection
on V-COCO
Ranked #9 on
Human-Object Interaction Detection
on V-COCO
Unsupervised Visual Representation Learning by Synchronous Momentum Grouping
In this paper, we propose a genuine group-level contrastive visual representation learning method whose linear evaluation performance on ImageNet surpasses the vanilla supervised learning.
 Ranked #38 on
Self-Supervised Image Classification
on <h2>oi</h2>
Ranked #38 on
Self-Supervised Image Classification
on <h2>oi</h2>
Unseen Object 6D Pose Estimation: A Benchmark and Baselines
In this paper, we propose a new task that enables and facilitates algorithms to estimate the 6D pose estimation of novel objects during testing.

Interactiveness Field in Human-Object Interactions
Human-Object Interaction (HOI) detection plays a core role in activity understanding.
Learning to Anticipate Future with Dynamic Context Removal
Anticipating future events is an essential feature for intelligent systems and embodied AI.
OakInk: A Large-scale Knowledge Repository for Understanding Hand-Object Interaction
We start to collect 1, 800 common household objects and annotate their affordances to construct the first knowledge base: Oak.
Semantic Segmentation by Early Region Proxy
Typical vision backbones manipulate structured features.
CPPF: Towards Robust Category-Level 9D Pose Estimation in the Wild
Drawing inspirations from traditional point pair features (PPFs), in this paper, we design a novel Category-level PPF (CPPF) voting method to achieve accurate, robust and generalizable 9D pose estimation in the wild.
 Ranked #8 on
6D Pose Estimation using RGBD
on REAL275
Ranked #8 on
6D Pose Estimation using RGBD
on REAL275

Highlighting Object Category Immunity for the Generalization of Human-Object Interaction Detection
To achieve OC-immunity, we propose an OC-immune network that decouples the inputs from OC, extracts OC-immune representations, and leverages uncertainty quantification to generalize to unseen objects.
TransCG: A Large-Scale Real-World Dataset for Transparent Object Depth Completion and a Grasping Baseline
However, the majority of current grasping algorithms would fail in this case since they heavily rely on the depth image, while ordinary depth sensors usually fail to produce accurate depth information for transparent objects owing to the reflection and refraction of light.
![]() Ranked #1 on
Transparent Object Depth Estimation
on TransCG
Ranked #1 on
Transparent Object Depth Estimation
on TransCG

AKB-48: A Real-World Articulated Object Knowledge Base
To bridge the gap, we present AKB-48: a large-scale Articulated object Knowledge Base which consists of 2, 037 real-world 3D articulated object models of 48 categories.
HAKE: A Knowledge Engine Foundation for Human Activity Understanding
Human activity understanding is of widespread interest in artificial intelligence and spans diverse applications like health care and behavior analysis.
Human Trajectory Prediction With Momentary Observation
Human trajectory prediction task aims to analyze human future movements given their past status, which is a crucial step for many autonomous systems such as self-driving cars and social robots.

iSeg3D: An Interactive 3D Shape Segmentation Tool
It can obtain a satisfied segmentation result with minimal human clicks (< 10).
OMAD: Object Model with Articulated Deformations for Pose Estimation and Retrieval
With the full representation of the object shape and joint states, we can address several tasks including category-level object pose estimation and the articulated object retrieval.
Regularity Learning via Explicit Distribution Modeling for Skeletal Video Anomaly Detection
Different from pixel-based anomaly detection methods, pose-based methods utilize highly-structured skeleton data, which decreases the computational burden and also avoids the negative impact of background noise.
Anomaly Detection In Surveillance Videos
 Optical Flow Estimation
+1
Optical Flow Estimation
+1
SAGCI-System: Towards Sample-Efficient, Generalizable, Compositional, and Incremental Robot Learning
We apply our system to perform articulated object manipulation tasks, both in the simulation and the real world.
Understanding Pixel-level 2D Image Semantics with 3D Keypoint Knowledge Engine
Pixel-level 2D object semantic understanding is an important topic in computer vision and could help machine deeply understand objects (e. g. functionality and affordance) in our daily life.
Skeleton-Based Mutually Assisted Interacted Object Localization and Human Action Recognition
Skeleton data carries valuable motion information and is widely explored in human action recognition.
Localization with Sampling-Argmax
In this work, we propose sampling-argmax, a differentiable training method that imposes implicit constraints to the shape of the probability map by minimizing the expectation of the localization error.
 Ranked #165 on
3D Human Pose Estimation
on Human3.6M
Ranked #165 on
3D Human Pose Estimation
on Human3.6M
Learning Single/Multi-Attribute of Object with Symmetry and Group
To model the compositional nature of these concepts, it is a good choice to learn them as transformations, e. g., coupling and decoupling.

ArtiBoost: Boosting Articulated 3D Hand-Object Pose Estimation via Online Exploration and Synthesis
In contrast, data synthesis can easily ensure those diversities separately.
 Ranked #3 on
hand-object pose
on HO-3D
(using extra training data)
Ranked #3 on
hand-object pose
on HO-3D
(using extra training data)

Human Pose Regression with Residual Log-likelihood Estimation
In light of this, we propose a novel regression paradigm with Residual Log-likelihood Estimation (RLE) to capture the underlying output distribution.
Ranked #63 on
3D Human Pose Estimation
on Human3.6M
ContourRender: Detecting Arbitrary Contour Shape For Instance Segmentation In One Pass
In addition, we specifically select a subset from COCO val2017 named COCO ContourHard-val to further demonstrate the contour quality improvements.


Towards Real-World Category-level Articulation Pose Estimation
This setting allows varied kinematic structures within a semantic category, and multiple instances to co-exist in an observation of real world.
H2O: A Benchmark for Visual Human-human Object Handover Analysis
Besides, we also report the hand and object pose errors with existing baselines and show that the dataset can serve as the video demonstrations for robot imitation learning on the handover task.
Skimming and Scanning for Untrimmed Video Action Recognition
Video action recognition (VAR) is a primary task of video understanding, and untrimmed videos are more common in real-life scenes.
SuctionNet-1Billion: A Large-Scale Benchmark for Suction Grasping
Meanwhile, we propose a method to predict numerous suction poses from an RGB-D image of a cluttered scene and demonstrate our superiority against several previous methods.
PGT: A Progressive Method for Training Models on Long Videos
This progressive training (PGT) method is able to train long videos end-to-end with limited resources and ensures the effective transmission of information.
Skeleton Merger: an Unsupervised Aligned Keypoint Detector
In this paper, we propose an unsupervised aligned keypoint detector, Skeleton Merger, which utilizes skeletons to reconstruct objects.

Three Steps to Multimodal Trajectory Prediction: Modality Clustering, Classification and Synthesis
Multimodal prediction results are essential for trajectory prediction task as there is no single correct answer for the future.

RGB Matters: Learning 7-DoF Grasp Poses on Monocular RGBD Images
In the first stage, an encoder-decoder like convolutional neural network Angle-View Net(AVN) is proposed to predict the SO(3) orientation of the gripper at every location of the image.
PRIN/SPRIN: On Extracting Point-wise Rotation Invariant Features
Spherical Voxel Convolution and Point Re-sampling are proposed to extract rotation invariant features for each point.
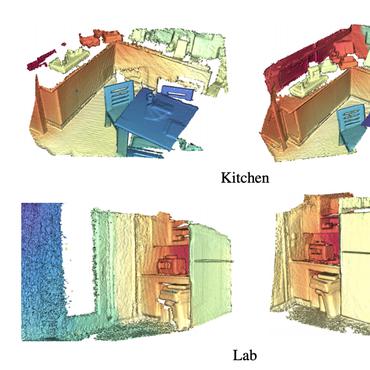
HandTailor: Towards High-Precision Monocular 3D Hand Recovery
3D hand pose estimation and shape recovery are challenging tasks in computer vision.

Transferable Interactiveness Knowledge for Human-Object Interaction Detection
Human-Object Interaction (HOI) detection is an important problem to understand how humans interact with objects.
Ranked #28 on
Human-Object Interaction Detection
on V-COCO
Graspness Discovery in Clutters for Fast and Accurate Grasp Detection
To quickly detect graspness in practice, we develop a neural network named graspness model to approximate the searching process.
 Ranked #3 on
Robotic Grasping
on GraspNet-1Billion
Ranked #3 on
Robotic Grasping
on GraspNet-1Billion
TDAF: Top-Down Attention Framework for Vision Tasks
Such spatial and attention features are nested deeply, therefore, the proposed framework works in a mixed top-down and bottom-up manner.
CPF: Learning a Contact Potential Field to Model the Hand-Object Interaction
In this paper, we present an explicit contact representation namely Contact Potential Field (CPF), and a learning-fitting hybrid framework namely MIHO to Modeling the Interaction of Hand and Object.
Learning Universal Shape Dictionary for Realtime Instance Segmentation
First, it learns a dictionary from a large collection of shape datasets, making any shape being able to be decomposed into a linear combination through the dictionary.
HybrIK: A Hybrid Analytical-Neural Inverse Kinematics Solution for 3D Human Pose and Shape Estimation
We show that HybrIK preserves both the accuracy of 3D pose and the realistic body structure of the parametric human model, leading to a pixel-aligned 3D body mesh and a more accurate 3D pose than the pure 3D keypoint estimation methods.
 Ranked #3 on
3D Human Pose Estimation
on EMDB
Ranked #3 on
3D Human Pose Estimation
on EMDB
Canonical Voting: Towards Robust Oriented Bounding Box Detection in 3D Scenes
In the work, we disentangle the direct offset into Local Canonical Coordinates (LCC), box scales and box orientations.

UKPGAN: A General Self-Supervised Keypoint Detector
Keypoint detection is an essential component for the object registration and alignment.
HOI Analysis: Integrating and Decomposing Human-Object Interaction
Meanwhile, isolated human and object can also be integrated into coherent HOI again.
Ranked #20 on
Human-Object Interaction Detection
on V-COCO
DecAug: Augmenting HOI Detection via Decomposition
Human-object interaction (HOI) detection requires a large amount of annotated data.
 Ranked #68 on
Domain Generalization
on PACS
Ranked #68 on
Domain Generalization
on PACS
DIRV: Dense Interaction Region Voting for End-to-End Human-Object Interaction Detection
On the other hand, existing one-stage methods mainly focus on the union regions of interactions, which introduce unnecessary visual information as disturbances to HOI detection.
Ranked #15 on
Human-Object Interaction Detection
on V-COCO
ASAP-Net: Attention and Structure Aware Point Cloud Sequence Segmentation
In this paper, we further improve spatio-temporal point cloud feature learning with a flexible module called ASAP considering both attention and structure information across frames, which we find as two important factors for successful segmentation in dynamic point clouds.
BiHand: Recovering Hand Mesh with Multi-stage Bisected Hourglass Networks
Inside each stage, BiHand adopts a novel bisecting design which allows the networks to encapsulate two closely related information (e. g. 2D keypoints and silhouette in 2D seeding stage, 3D joints, and depth map in 3D lifting stage, joint rotations and shape parameters in the mesh generation stage) in a single forward pass.
HMOR: Hierarchical Multi-Person Ordinal Relations for Monocular Multi-Person 3D Pose Estimation
The HMOR encodes interaction information as the ordinal relations of depths and angles hierarchically, which captures the body-part and joint level semantic and maintains global consistency at the same time.

 3D Multi-Person Pose Estimation (absolute)
3D Multi-Person Pose Estimation (absolute)
 3D Multi-Person Pose Estimation (root-relative)
+2
3D Multi-Person Pose Estimation (root-relative)
+2
Approximated Bilinear Modules for Temporal Modeling
Specifically, we show how two-layer subnets in CNNs can be converted to temporal bilinear modules by adding an auxiliary-branch.
TubeTK: Adopting Tubes to Track Multi-Object in a One-Step Training Model
As deep learning brings excellent performances to object detection algorithms, Tracking by Detection (TBD) has become the mainstream tracking framework.
Complex Sequential Understanding through the Awareness of Spatial and Temporal Concepts
Understanding sequential information is a fundamental task for artificial intelligence.
NTIRE 2020 Challenge on Video Quality Mapping: Methods and Results
For track 2, some existing methods are evaluated, showing promising solutions to the weakly-supervised video quality mapping problem.
Transferable Active Grasping and Real Embodied Dataset
Grasping in cluttered scenes is challenging for robot vision systems, as detection accuracy can be hindered by partial occlusion of objects.
Recursive Social Behavior Graph for Trajectory Prediction
Social interaction is an important topic in human trajectory prediction to generate plausible paths.
Semantic Correspondence via 2D-3D-2D Cycle
Visual semantic correspondence is an important topic in computer vision and could help machine understand objects in our daily life.
Detailed 2D-3D Joint Representation for Human-Object Interaction
In light of these, we propose a detailed 2D-3D joint representation learning method.
 Ranked #1 on
Human-Object Interaction Detection
on Ambiguious-HOI
Ranked #1 on
Human-Object Interaction Detection
on Ambiguious-HOI
Asynchronous Interaction Aggregation for Action Detection
We propose the Asynchronous Interaction Aggregation network (AIA) that leverages different interactions to boost action detection.

PaStaNet: Toward Human Activity Knowledge Engine
In light of this, we propose a new path: infer human part states first and then reason out the activities based on part-level semantics.
 Ranked #3 on
Human-Object Interaction Detection
on HICO
Ranked #3 on
Human-Object Interaction Detection
on HICO
Symmetry and Group in Attribute-Object Compositions
To model the compositional nature of these general concepts, it is a good choice to learn them through transformations, such as coupling and decoupling.
 Ranked #1 on
Compositional Zero-Shot Learning
on MIT-States
(Top-1 accuracy % metric)
Ranked #1 on
Compositional Zero-Shot Learning
on MIT-States
(Top-1 accuracy % metric)
KeypointNet: A Large-scale 3D Keypoint Dataset Aggregated from Numerous Human Annotations
Detecting 3D objects keypoints is of great interest to the areas of both graphics and computer vision.
Deep Variational Luenberger-type Observer for Stochastic Video Prediction
Our model builds upon an variational encoder which transforms the input video into a latent feature space and a Luenberger-type observer which captures the dynamic evolution of the latent features.

GraspNet: A Large-Scale Clustered and Densely Annotated Dataset for Object Grasping
Object grasping is critical for many applications, which is also a challenging computer vision problem.
Human Correspondence Consensus for 3D Object Semantic Understanding
Semantic understanding of 3D objects is crucial in many applications such as object manipulation.

3D Objectness Estimation via Bottom-up Regret Grouping
Further ablation study also demonstrates the effectiveness of our grouping predictor and regret mechanism.
Transferable Force-Torque Dynamics Model for Peg-in-hole Task
We present a learning-based force-torque dynamics to achieve model-based control for contact-rich peg-in-hole task using force-only inputs.
Attribute Restoration Framework for Anomaly Detection
We here propose to break this equivalence by erasing selected attributes from the original data and reformulate it as a restoration task, where the normal and the anomalous data are expected to be distinguishable based on restoration errors.
 Ranked #21 on
Anomaly Detection
on One-class CIFAR-10
Ranked #21 on
Anomaly Detection
on One-class CIFAR-10

6-PACK: Category-level 6D Pose Tracker with Anchor-Based Keypoints
We present 6-PACK, a deep learning approach to category-level 6D object pose tracking on RGB-D data.
Ranked #1 on
6D Pose Estimation using RGBD
on REAL275
(Rerr metric)
RGB-D Individual Segmentation
Fine-grained recognition task deals with sub-category classification problem, which is important for real-world applications.
Template-Instance Loss for Offline Handwritten Chinese Character Recognition
The long-standing challenges for offline handwritten Chinese character recognition (HCCR) are twofold: Chinese characters can be very diverse and complicated while similarly looking, and cursive handwriting (due to increased writing speed and infrequent pen lifting) makes strokes and even characters connected together in a flowing manner.
InstaBoost: Boosting Instance Segmentation via Probability Map Guided Copy-Pasting
With the guidance of such map, we boost the performance of R101-Mask R-CNN on instance segmentation from 35. 7 mAP to 37. 9 mAP without modifying the backbone or network structure.
 Ranked #78 on
Instance Segmentation
on COCO test-dev
Ranked #78 on
Instance Segmentation
on COCO test-dev
Cross-Domain Adaptation for Animal Pose Estimation
Therefore, the easily available human pose dataset, which is of a much larger scale than our labeled animal dataset, provides important prior knowledge to boost up the performance on animal pose estimation.


Three Branches: Detecting Actions With Richer Features
We present our three branch solutions for International Challenge on Activity Recognition at CVPR2019.
Explicit Shape Encoding for Real-Time Instance Segmentation
In this paper, we propose a novel top-down instance segmentation framework based on explicit shape encoding, named \textbf{ESE-Seg}.
 Ranked #3 on
Semantic Contour Prediction
on Sbd val
Ranked #3 on
Semantic Contour Prediction
on Sbd val
HAKE: Human Activity Knowledge Engine
To address these and promote the activity understanding, we build a large-scale Human Activity Knowledge Engine (HAKE) based on the human body part states.
Ranked #2 on
Human-Object Interaction Detection
on HICO
(using extra training data)
Combinational Q-Learning for Dou Di Zhu
Deep reinforcement learning (DRL) has gained a lot of attention in recent years, and has been proven to be able to play Atari games and Go at or above human levels.


DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion
A key technical challenge in performing 6D object pose estimation from RGB-D image is to fully leverage the two complementary data sources.
 Ranked #4 on
6D Pose Estimation
on LineMOD
Ranked #4 on
6D Pose Estimation
on LineMOD
Estimating 6D Pose From Localizing Designated Surface Keypoints
In this paper, we present an accurate yet effective solution for 6D pose estimation from an RGB image.
 Ranked #17 on
6D Pose Estimation using RGB
on LineMOD
Ranked #17 on
6D Pose Estimation using RGB
on LineMOD

CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark
In this paper, we propose a novel and efficient method to tackle the problem of pose estimation in the crowd and a new dataset to better evaluate algorithms.
 Ranked #6 on
Multi-Person Pose Estimation
on OCHuman
Ranked #6 on
Multi-Person Pose Estimation
on OCHuman
Deep RNN Framework for Visual Sequential Applications
There are mainly two novel designs in our deep RNN framework: one is a new RNN module called Context Bridge Module (CBM) which splits the information flowing along the sequence (temporal direction) and along depth (spatial representation direction), making it easier to train when building deep by balancing these two directions; the other is the Overlap Coherence Training Scheme that reduces the training complexity for long visual sequential tasks on account of the limitation of computing resources.
Pointwise Rotation-Invariant Network with Adaptive Sampling and 3D Spherical Voxel Convolution
Point cloud analysis without pose priors is very challenging in real applications, as the orientations of point clouds are often unknown.
Transferable Interactiveness Knowledge for Human-Object Interaction Detection
On account of the generalization of interactiveness, interactiveness network is a transferable knowledge learner and can be cooperated with any HOI detection models to achieve desirable results.
Ranked #29 on
Human-Object Interaction Detection
on V-COCO
NavigationNet: A Large-scale Interactive Indoor Navigation Dataset
Indoor navigation aims at performing navigation within buildings.
Pairwise Body-Part Attention for Recognizing Human-Object Interactions
We propose a new pairwise body-part attention model which can learn to focus on crucial parts, and their correlations for HOI recognition.
Ranked #5 on
Human-Object Interaction Detection
on HICO
AXNet: ApproXimate computing using an end-to-end trainable neural network
To guarantee the approximation quality, existing works deploy two neural networks (NNs), e. g., an approximator and a predictor.

PointSIFT: A SIFT-like Network Module for 3D Point Cloud Semantic Segmentation
Recently, 3D understanding research sheds light on extracting features from point cloud directly, which requires effective shape pattern description of point clouds.
LiDAR-Video Driving Dataset: Learning Driving Policies Effectively
Learning autonomous-driving policies is one of the most challenging but promising tasks for computer vision.
Environment Upgrade Reinforcement Learning for Non-Differentiable Multi-Stage Pipelines
We propose a training algorithm for this framework to address the different training demands of agent and environment.
Weakly and Semi Supervised Human Body Part Parsing via Pose-Guided Knowledge Transfer
In this paper, we present a novel method to generate synthetic human part segmentation data using easily-obtained human keypoint annotations.
 Ranked #4 on
Human Part Segmentation
on PASCAL-Part
(using extra training data)
Ranked #4 on
Human Part Segmentation
on PASCAL-Part
(using extra training data)

Recurrent Residual Module for Fast Inference in Videos
Deep convolutional neural networks (CNNs) have made impressive progress in many video recognition tasks such as video pose estimation and video object detection.
Human Action Adverb Recognition: ADHA Dataset and A Three-Stream Hybrid Model
We introduce the first benchmark for a new problem --- recognizing human action adverbs (HAA): "Adverbs Describing Human Actions" (ADHA).

Pose Flow: Efficient Online Pose Tracking
Multi-person articulated pose tracking in unconstrained videos is an important while challenging problem.
![]() Ranked #9 on
Pose Tracking
on PoseTrack2017
(using extra training data)
Ranked #9 on
Pose Tracking
on PoseTrack2017
(using extra training data)
Annotation-Free and One-Shot Learning for Instance Segmentation of Homogeneous Object Clusters
We propose a novel approach for instance segmen- tation given an image of homogeneous object clus- ter (HOC).

SRDA: Generating Instance Segmentation Annotation Via Scanning, Reasoning And Domain Adaptation
Instance segmentation is a problem of significance in computer vision.
TRL: Discriminative Hints for Scalable Reverse Curriculum Learning
However, tasks with sparse rewards remain challenging when the state space is large.
Online Video Object Detection Using Association LSTM
Video object detection is a fundamental tool for many applications.
Virtual to Real Reinforcement Learning for Autonomous Driving
To our knowledge, this is the first successful case of driving policy trained by reinforcement learning that can adapt to real world driving data.
Beyond Holistic Object Recognition: Enriching Image Understanding with Part States
Important high-level vision tasks such as human-object interaction, image captioning and robotic manipulation require rich semantic descriptions of objects at part level.
RMPE: Regional Multi-person Pose Estimation
In this paper, we propose a novel regional multi-person pose estimation (RMPE) framework to facilitate pose estimation in the presence of inaccurate human bounding boxes.
 Ranked #1 on
Pose Estimation
on UAV-Human
Ranked #1 on
Pose Estimation
on UAV-Human
Visual Relationship Detection with Language Priors
We improve on prior work by leveraging language priors from semantic word embeddings to finetune the likelihood of a predicted relationship.
 Ranked #2 on
Scene Graph Generation
on VRD
Ranked #2 on
Scene Graph Generation
on VRD
Contour Box: Rejecting Object Proposals Without Explicit Closed Contours
Closed contour is an important objectness indicator.
Box Aggregation for Proposal Decimation: Last Mile of Object Detection
Regions-with-convolutional-neural-network (RCNN) is now a commonly employed object detection pipeline.
Square Localization for Efficient and Accurate Object Detection
In the testing phase, sliding CNN models are applied which produces a set of response maps that can be effectively filtered by the learned co-presence prior to output the final bounding boxes for localizing an object.
Complexity-Adaptive Distance Metric for Object Proposals Generation
Distance metric plays a key role in grouping superpixels to produce object proposals for object detection.
Deep LAC: Deep Localization, Alignment and Classification for Fine-Grained Recognition
Our major contribution is to propose a valve linkage function(VLF) for back-propagation chaining and form our deep localization, alignment and classification (LAC) system.

1-HKUST: Object Detection in ILSVRC 2014
We participated in the object detection track of ILSVRC 2014 and received the fourth place among the 38 teams.
L0 Regularized Stationary Time Estimation for Crowd Group Analysis
We tackle stationary crowd analysis in this paper, which is similarly important as modeling mobile groups in crowd scenes and finds many applications in surveillance.
Learning Important Spatial Pooling Regions for Scene Classification
We address the false response influence problem when learning and applying discriminative parts to construct the mid-level representation in scene classification.
Two-Class Weather Classification
Given a single outdoor image, this paper proposes a collaborative learning approach for labeling it as either sunny or cloudy.
Online Robust Dictionary Learning
Online dictionary learning is particularly useful for processing large-scale and dynamic data in computer vision.
