 Transformers
Transformers
GPT-3
Introduced by Brown et al. in Language Models are Few-Shot LearnersGPT-3 is an autoregressive transformer model with 175 billion parameters. It uses the same architecture/model as GPT-2, including the modified initialization, pre-normalization, and reversible tokenization, with the exception that GPT-3 uses alternating dense and locally banded sparse attention patterns in the layers of the transformer, similar to the Sparse Transformer.
Source: Language Models are Few-Shot Learners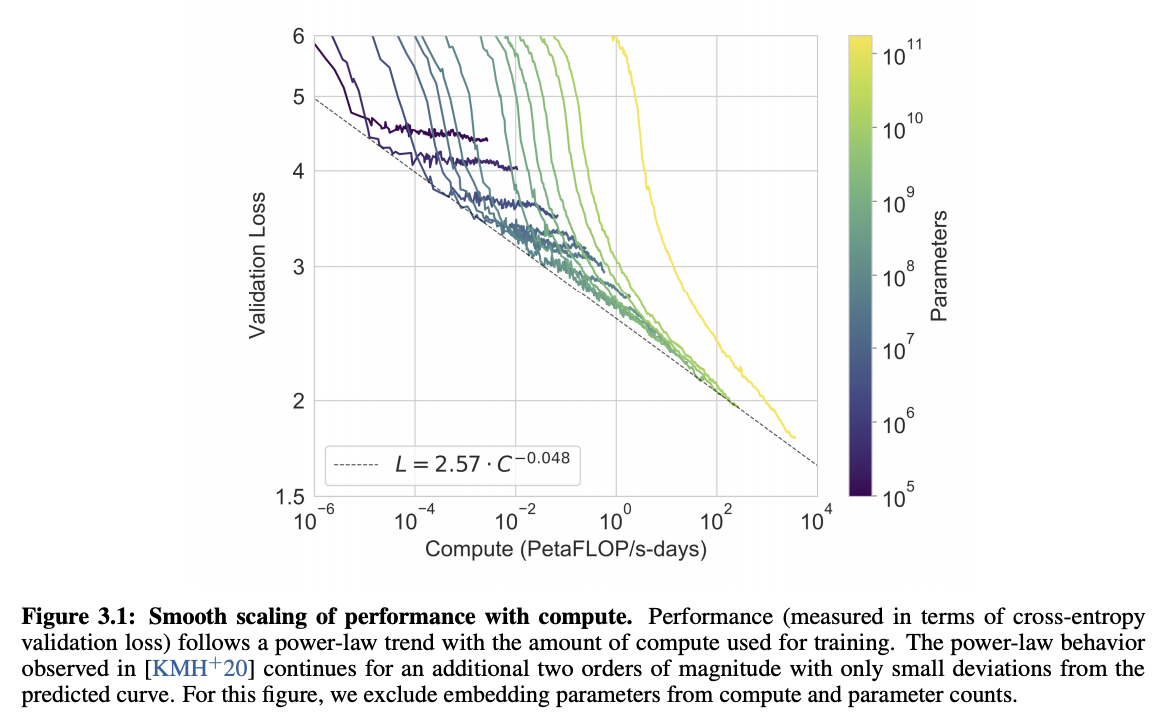
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Language Modelling | 76 | 10.04% |
| Question Answering | 49 | 6.47% |
| Large Language Model | 47 | 6.21% |
| In-Context Learning | 33 | 4.36% |
| Retrieval | 31 | 4.10% |
| Code Generation | 28 | 3.70% |
| Prompt Engineering | 27 | 3.57% |
| Sentence | 23 | 3.04% |
| Text Generation | 19 | 2.51% |
 Adam
Adam
 Attention Dropout
Attention Dropout
 BPE
BPE
 Dense Connections
Dense Connections
 Dropout
Dropout
 Fixed Factorized Attention
Fixed Factorized Attention
 GELU
GELU
 Layer Normalization
Layer Normalization
 Linear Warmup With Cosine Annealing
Linear Warmup With Cosine Annealing
 Multi-Head Attention
Multi-Head Attention
 Residual Connection
Residual Connection
 Scaled Dot-Product Attention
Scaled Dot-Product Attention
 Softmax
Softmax
 Strided Attention
Strided Attention
 Weight Decay
Weight Decay


