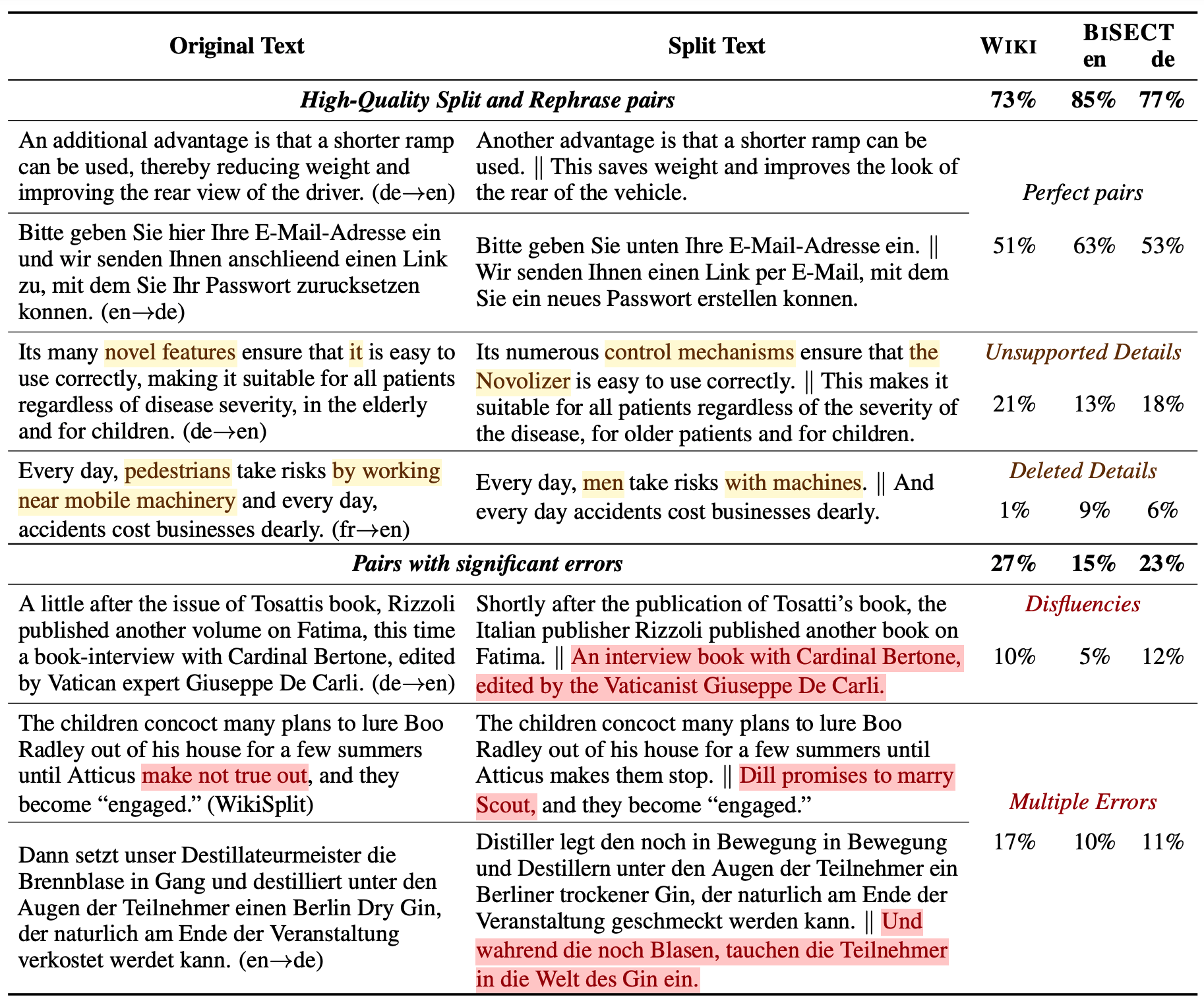
BiSECT is a dataset for sentence simplification, which is the ability to take a long, complex sentence and split it into shorter sentences, rephrasing as necessary. BiSECT training data consists of 1 million long English sentences paired with shorter, meaning-equivalent English sentences. These were obtained by extracting 1-2 sentence alignments in bilingual parallel corpora and then using machine translation to convert both sides of the corpus into the same language.
Papers
| Paper | Code | Results | Date | Stars |
|---|
Dataset Loaders
No data loaders found. You can
submit your data loader here.
No data loaders found. You can
submit your data loader here.
