CALVIN (Composing Actions from Language and Vision)
Introduced by Mees et al. in CALVIN: A Benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks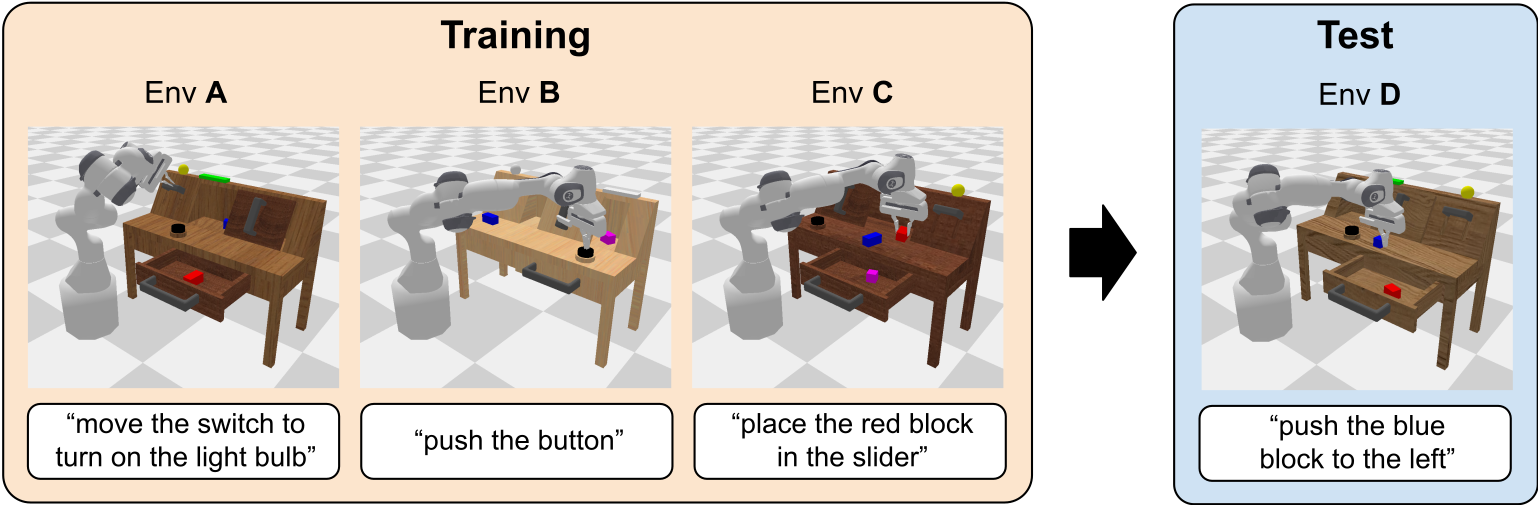
CALVIN (Composing Actions from Language and Vision), is an open-source simulated benchmark to learn long-horizon language-conditioned robot manipulation tasks.
Benchmarks
| Trend | Task | Dataset Variant | Best Model | Paper | Code |
|---|---|---|---|---|---|

|
CALVIN
|
3D Diffuser Actor
|
|||

|
CALVIN
|
HULC++
|
|||

|
CALVIN
|
HULC++
|
Papers
| Paper | Code | Results | Date | Stars |
|---|

