SNIPS (SNIPS Natural Language Understanding benchmark)
Introduced by Coucke et al. in Snips Voice Platform: an embedded Spoken Language Understanding system for private-by-design voice interfaces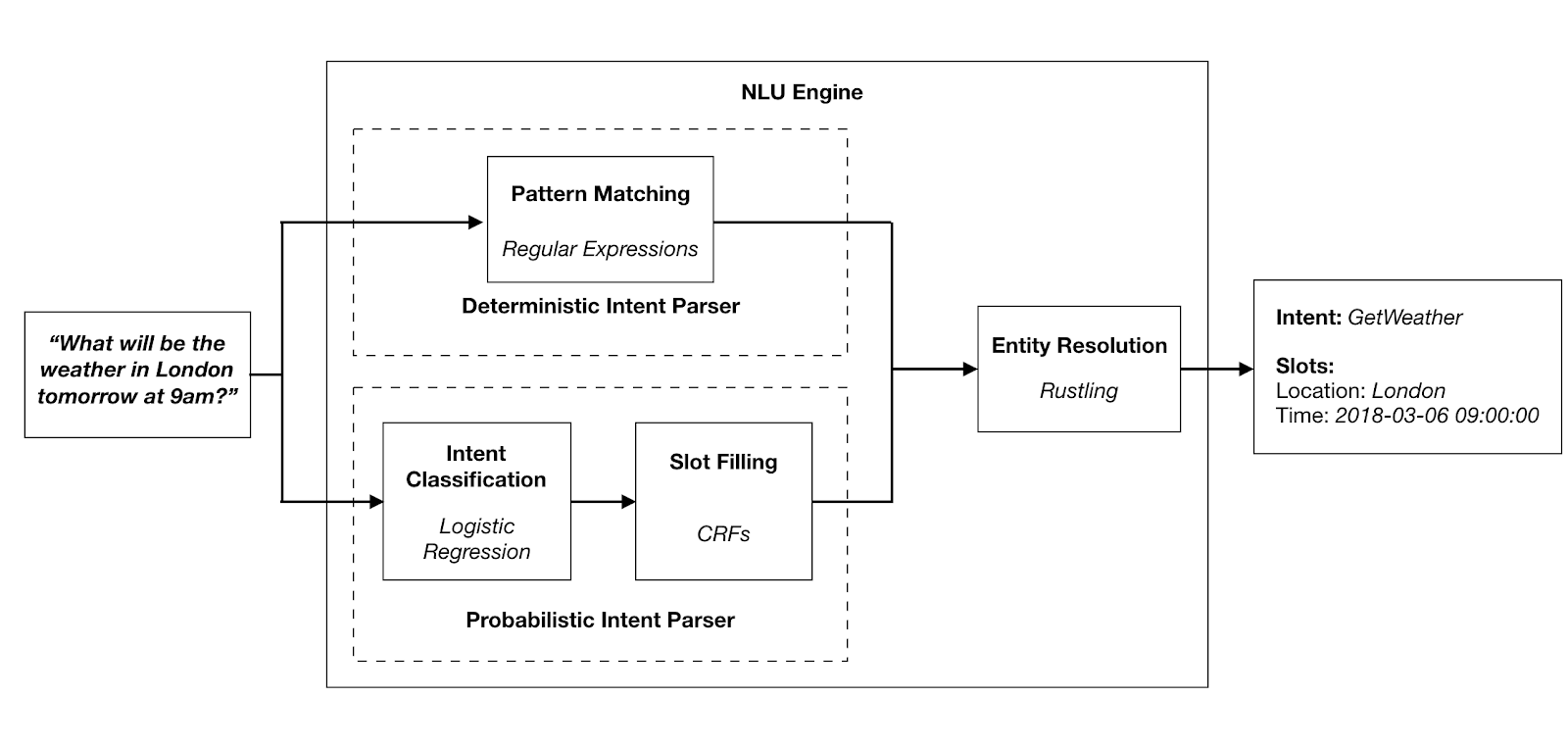
The SNIPS Natural Language Understanding benchmark is a dataset of over 16,000 crowdsourced queries distributed among 7 user intents of various complexity:
- SearchCreativeWork (e.g. Find me the I, Robot television show),
- GetWeather (e.g. Is it windy in Boston, MA right now?),
- BookRestaurant (e.g. I want to book a highly rated restaurant in Paris tomorrow night),
- PlayMusic (e.g. Play the last track from Beyoncé off Spotify),
- AddToPlaylist (e.g. Add Diamonds to my roadtrip playlist),
- RateBook (e.g. Give 6 stars to Of Mice and Men),
- SearchScreeningEvent (e.g. Check the showtimes for Wonder Woman in Paris). The training set contains of 13,084 utterances, the validation set and the test set contain 700 utterances each, with 100 queries per intent.
Benchmarks
| Trend | Task | Dataset Variant | Best Model | Paper | Code |
|---|---|---|---|---|---|

|
SNIPS
|
CTRAN
|
|||

|
SNIPS
|
CTRAN
|
|||

|
SNIPS
|
DSSCC
|
|||

|
SNIPS
|
ZSL-KG
|
|||

|
SNIPS
|
BERT + VAE
|
|||

|
SNIPS
|
k-PCA + HDBSCAN
|
Papers
| Paper | Code | Results | Date | Stars |
|---|








