Restricted Recurrent Neural Networks
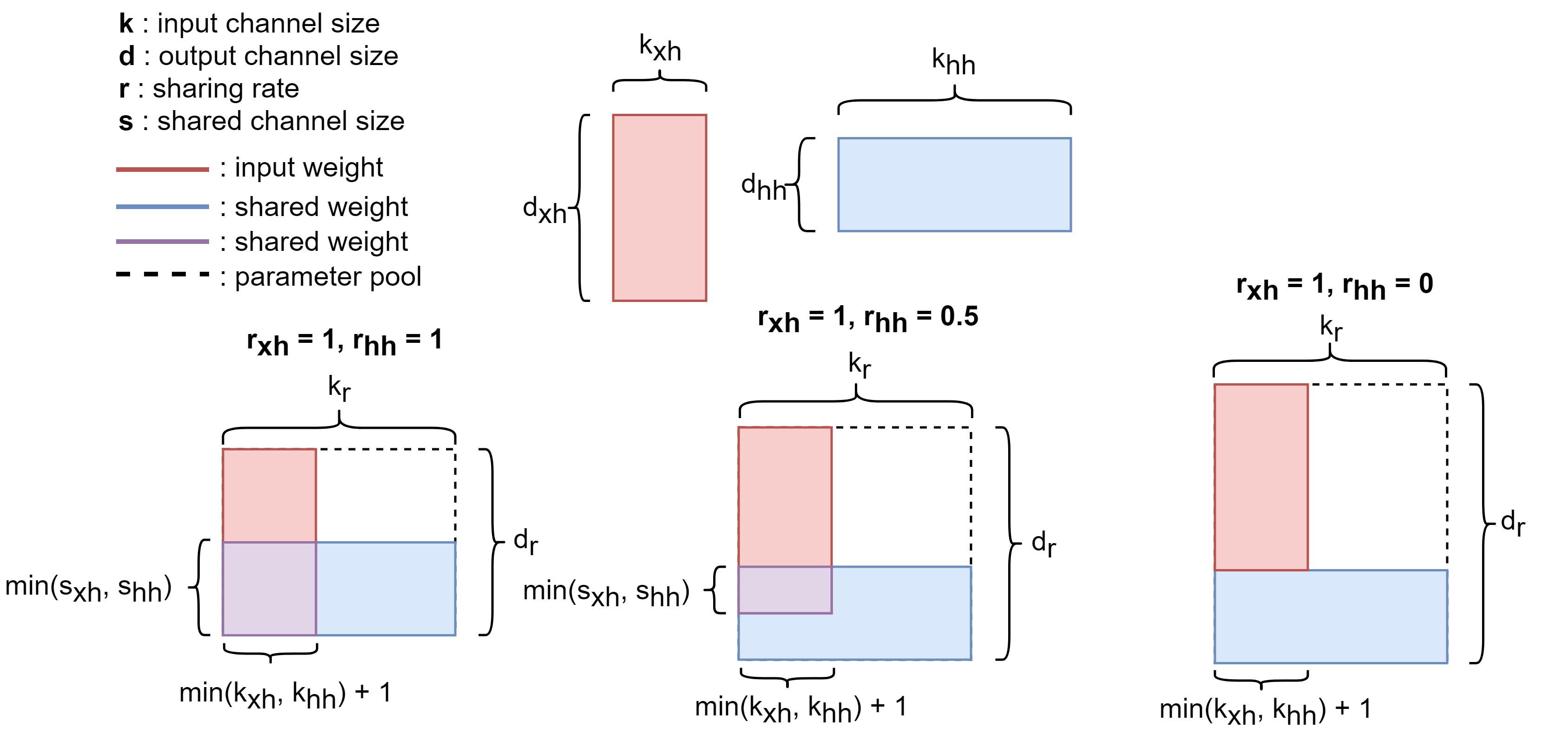
Recurrent Neural Network (RNN) and its variations such as Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU), have become standard building blocks for learning online data of sequential nature in many research areas, including natural language processing and speech data analysis. In this paper, we present a new methodology to significantly reduce the number of parameters in RNNs while maintaining performance that is comparable or even better than classical RNNs. The new proposal, referred to as Restricted Recurrent Neural Network (RRNN), restricts the weight matrices corresponding to the input data and hidden states at each time step to share a large proportion of parameters. The new architecture can be regarded as a compression of its classical counterpart, but it does not require pre-training or sophisticated parameter fine-tuning, both of which are major issues in most existing compression techniques. Experiments on natural language modeling show that compared with its classical counterpart, the restricted recurrent architecture generally produces comparable results at about 50\% compression rate. In particular, the Restricted LSTM can outperform classical RNN with even less number of parameters.
PDF Abstract

 Penn Treebank
Penn Treebank
 WikiText-2
WikiText-2
