Improving Generative Visual Dialog by Answering Diverse Questions
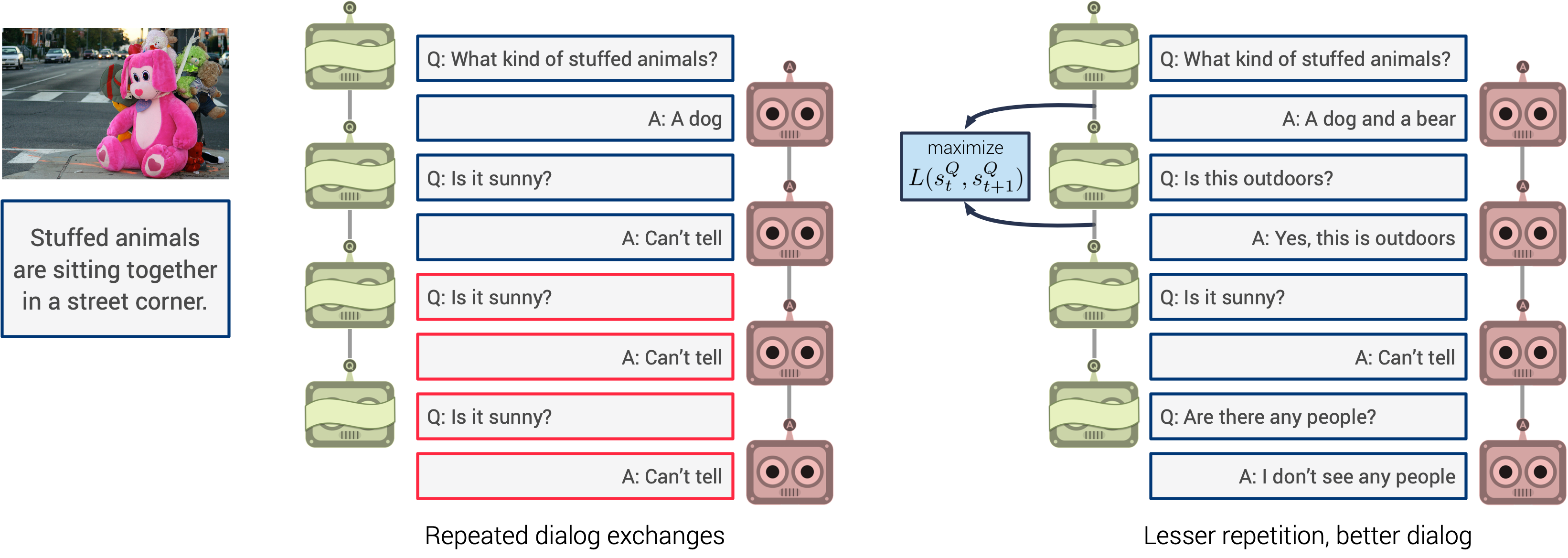
Prior work on training generative Visual Dialog models with reinforcement learning(Das et al.) has explored a Qbot-Abot image-guessing game and shown that this 'self-talk' approach can lead to improved performance at the downstream dialog-conditioned image-guessing task. However, this improvement saturates and starts degrading after a few rounds of interaction, and does not lead to a better Visual Dialog model. We find that this is due in part to repeated interactions between Qbot and Abot during self-talk, which are not informative with respect to the image. To improve this, we devise a simple auxiliary objective that incentivizes Qbot to ask diverse questions, thus reducing repetitions and in turn enabling Abot to explore a larger state space during RL ie. be exposed to more visual concepts to talk about, and varied questions to answer. We evaluate our approach via a host of automatic metrics and human studies, and demonstrate that it leads to better dialog, ie. dialog that is more diverse (ie. less repetitive), consistent (ie. has fewer conflicting exchanges), fluent (ie. more human-like),and detailed, while still being comparably image-relevant as prior work and ablations.
PDF Abstract IJCNLP 2019 PDF IJCNLP 2019 Abstract


 VisDial
VisDial
