Evaluating the Factual Consistency of Abstractive Text Summarization
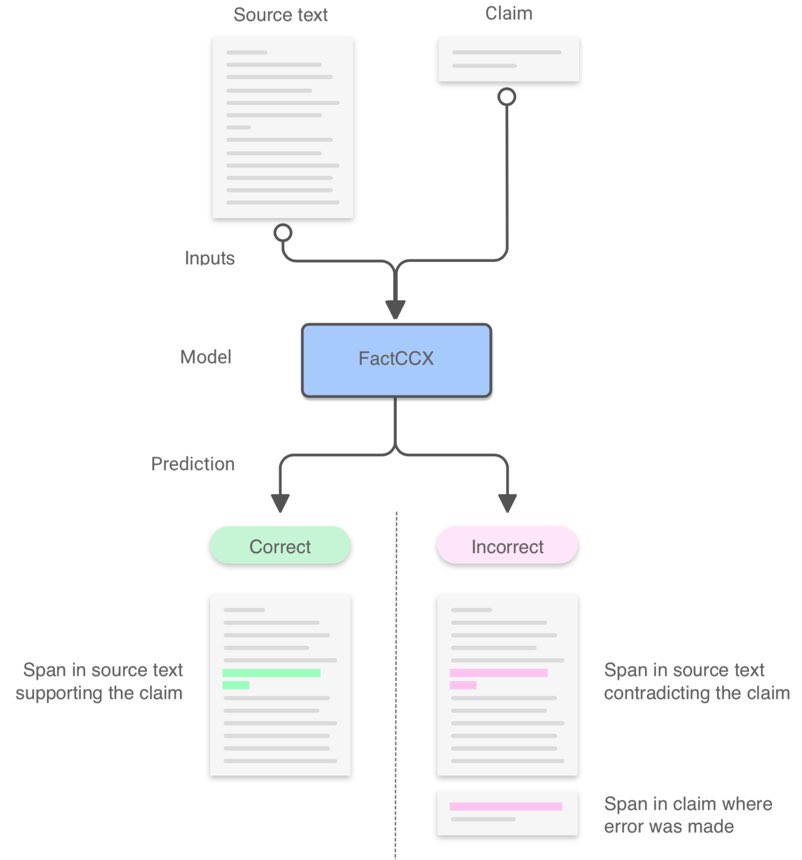
Currently used metrics for assessing summarization algorithms do not account for whether summaries are factually consistent with source documents. We propose a weakly-supervised, model-based approach for verifying factual consistency and identifying conflicts between source documents and a generated summary. Training data is generated by applying a series of rule-based transformations to the sentences of source documents. The factual consistency model is then trained jointly for three tasks: 1) identify whether sentences remain factually consistent after transformation, 2) extract a span in the source documents to support the consistency prediction, 3) extract a span in the summary sentence that is inconsistent if one exists. Transferring this model to summaries generated by several state-of-the art models reveals that this highly scalable approach substantially outperforms previous models, including those trained with strong supervision using standard datasets for natural language inference and fact checking. Additionally, human evaluation shows that the auxiliary span extraction tasks provide useful assistance in the process of verifying factual consistency.
PDF Abstract EMNLP 2020 PDF EMNLP 2020 Abstract





 MultiNLI
MultiNLI
 CNN/Daily Mail
CNN/Daily Mail
 FEVER
FEVER
