Hate-Alert@DravidianLangTech-EACL2021: Ensembling strategies for Transformer-based Offensive language Detection
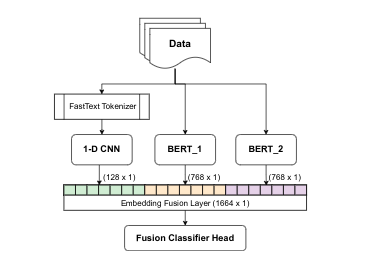
Social media often acts as breeding grounds for different forms of offensive content. For low resource languages like Tamil, the situation is more complex due to the poor performance of multilingual or language-specific models and lack of proper benchmark datasets. Based on this shared task, Offensive Language Identification in Dravidian Languages at EACL 2021, we present an exhaustive exploration of different transformer models, We also provide a genetic algorithm technique for ensembling different models. Our ensembled models trained separately for each language secured the first position in Tamil, the second position in Kannada, and the first position in Malayalam sub-tasks. The models and codes are provided.
PDF Abstract EACL (DravidianLangTech) 2021 PDF EACL (DravidianLangTech) 2021 Abstract

Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
