The Gutenberg Dialogue Dataset
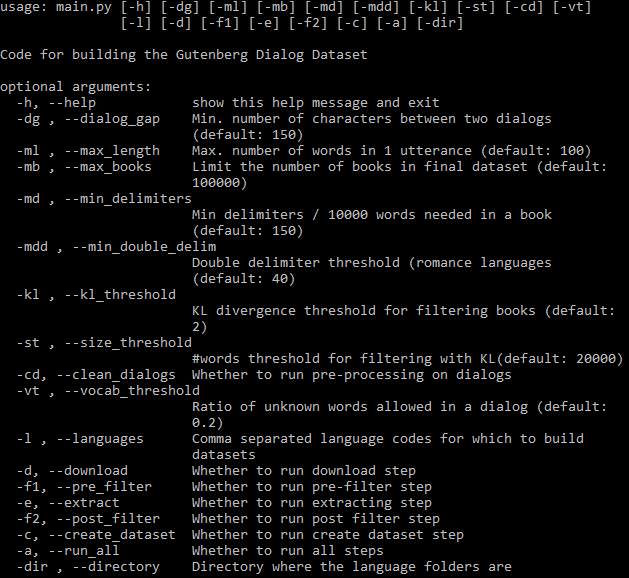
Large datasets are essential for neural modeling of many NLP tasks. Current publicly available open-domain dialogue datasets offer a trade-off between quality (e.g., DailyDialog) and size (e.g., Opensubtitles). We narrow this gap by building a high-quality dataset of 14.8M utterances in English, and smaller datasets in German, Dutch, Spanish, Portuguese, Italian, and Hungarian. We extract and process dialogues from public-domain books made available by Project Gutenberg. We describe our dialogue extraction pipeline, analyze the effects of the various heuristics used, and present an error analysis of extracted dialogues. Finally, we conduct experiments showing that better response quality can be achieved in zero-shot and finetuning settings by training on our data than on the larger but much noisier Opensubtitles dataset. Our open-source pipeline (https://github.com/ricsinaruto/gutenberg-dialog) can be extended to further languages with little additional effort. Researchers can also build their versions of existing datasets by adjusting various trade-off parameters. We also built a web demo for interacting with our models: https://ricsinaruto.github.io/chatbot.html.
PDF Abstract EACL 2021 PDF EACL 2021 Abstract DailyDialog
DailyDialog
 PERSONA-CHAT
PERSONA-CHAT
