A Fine-Grained Spectral Perspective on Neural Networks
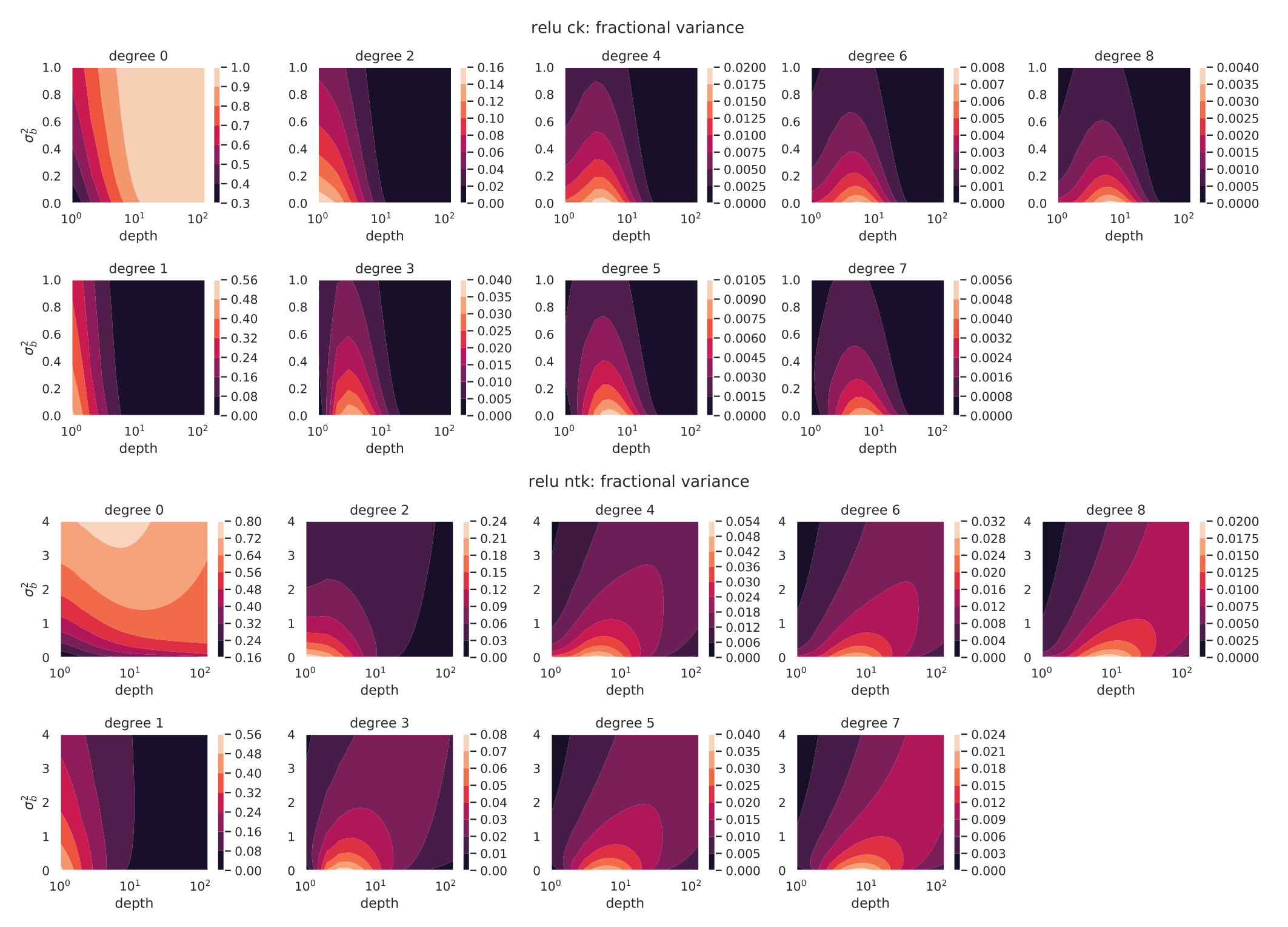
Are neural networks biased toward simple functions? Does depth always help learn more complex features? Is training the last layer of a network as good as training all layers? How to set the range for learning rate tuning? These questions seem unrelated at face value, but in this work we give all of them a common treatment from the spectral perspective. We will study the spectra of the *Conjugate Kernel, CK,* (also called the *Neural Network-Gaussian Process Kernel*), and the *Neural Tangent Kernel, NTK*. Roughly, the CK and the NTK tell us respectively "what a network looks like at initialization" and "what a network looks like during and after training." Their spectra then encode valuable information about the initial distribution and the training and generalization properties of neural networks. By analyzing the eigenvalues, we lend novel insights into the questions put forth at the beginning, and we verify these insights by extensive experiments of neural networks. We derive fast algorithms for computing the spectra of CK and NTK when the data is uniformly distributed over the boolean cube, and show this spectra is the same in high dimensions when data is drawn from isotropic Gaussian or uniformly over the sphere. Code replicating our results is available at github.com/thegregyang/NNspectra.
PDF Abstract
