A Hitchhiker's Guide to Statistical Comparisons of Reinforcement Learning Algorithms
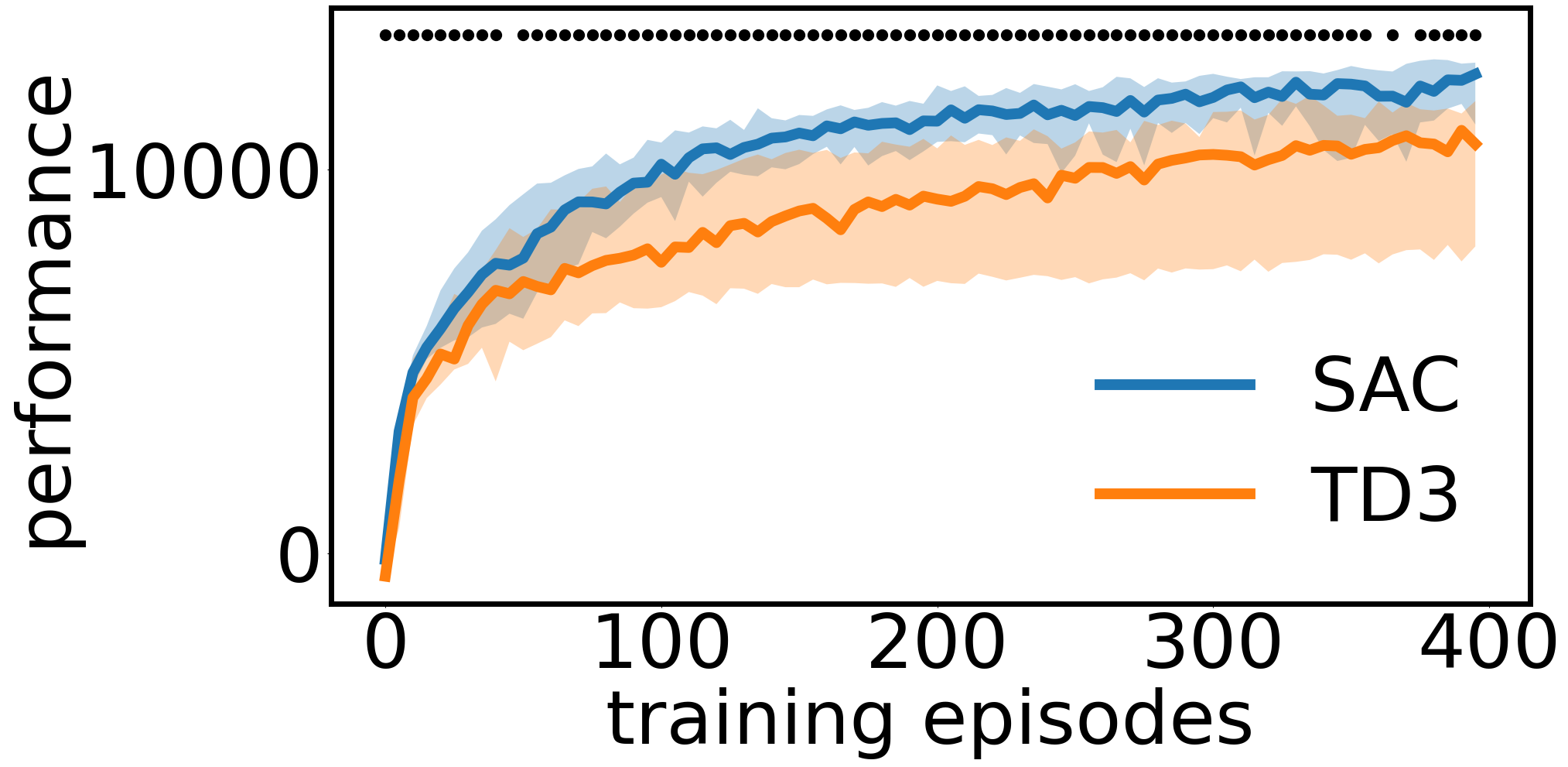
Consistently checking the statistical significance of experimental results is the first mandatory step towards reproducible science. This paper presents a hitchhiker's guide to rigorous comparisons of reinforcement learning algorithms. After introducing the concepts of statistical testing, we review the relevant statistical tests and compare them empirically in terms of false positive rate and statistical power as a function of the sample size (number of seeds) and effect size. We further investigate the robustness of these tests to violations of the most common hypotheses (normal distributions, same distributions, equal variances). Beside simulations, we compare empirical distributions obtained by running Soft-Actor Critic and Twin-Delayed Deep Deterministic Policy Gradient on Half-Cheetah. We conclude by providing guidelines and code to perform rigorous comparisons of RL algorithm performances.
PDF Abstract
