A Neural State-Space Model Approach to Efficient Speech Separation
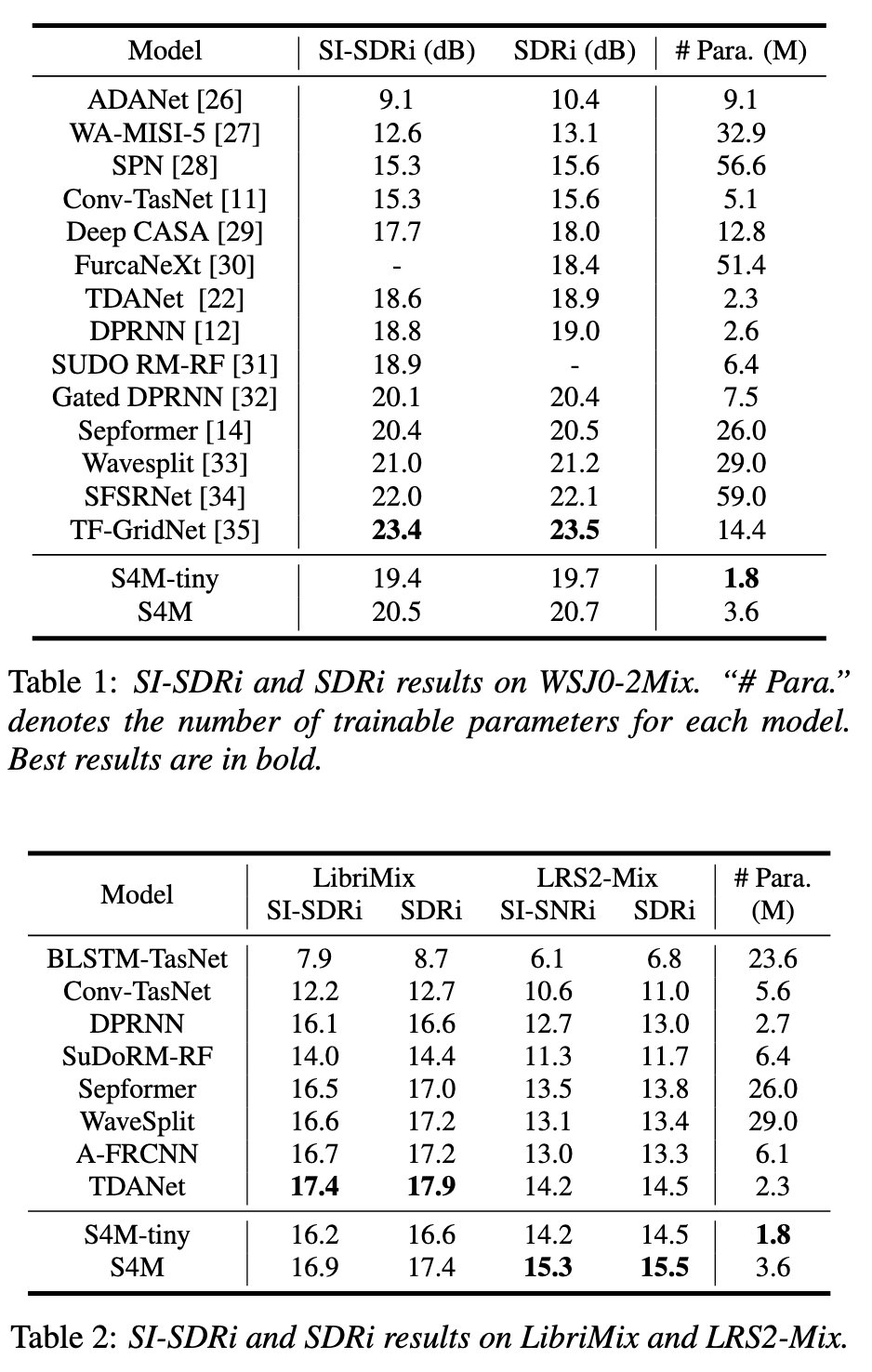
In this work, we introduce S4M, a new efficient speech separation framework based on neural state-space models (SSM). Motivated by linear time-invariant systems for sequence modeling, our SSM-based approach can efficiently model input signals into a format of linear ordinary differential equations (ODEs) for representation learning. To extend the SSM technique into speech separation tasks, we first decompose the input mixture into multi-scale representations with different resolutions. This mechanism enables S4M to learn globally coherent separation and reconstruction. The experimental results show that S4M performs comparably to other separation backbones in terms of SI-SDRi, while having a much lower model complexity with significantly fewer trainable parameters. In addition, our S4M-tiny model (1.8M parameters) even surpasses attention-based Sepformer (26.0M parameters) in noisy conditions with only 9.2 of multiply-accumulate operation (MACs).
PDF Abstract


 WSJ0-2mix
WSJ0-2mix
 LRS2
LRS2
