A Rationale-Centric Framework for Human-in-the-loop Machine Learning
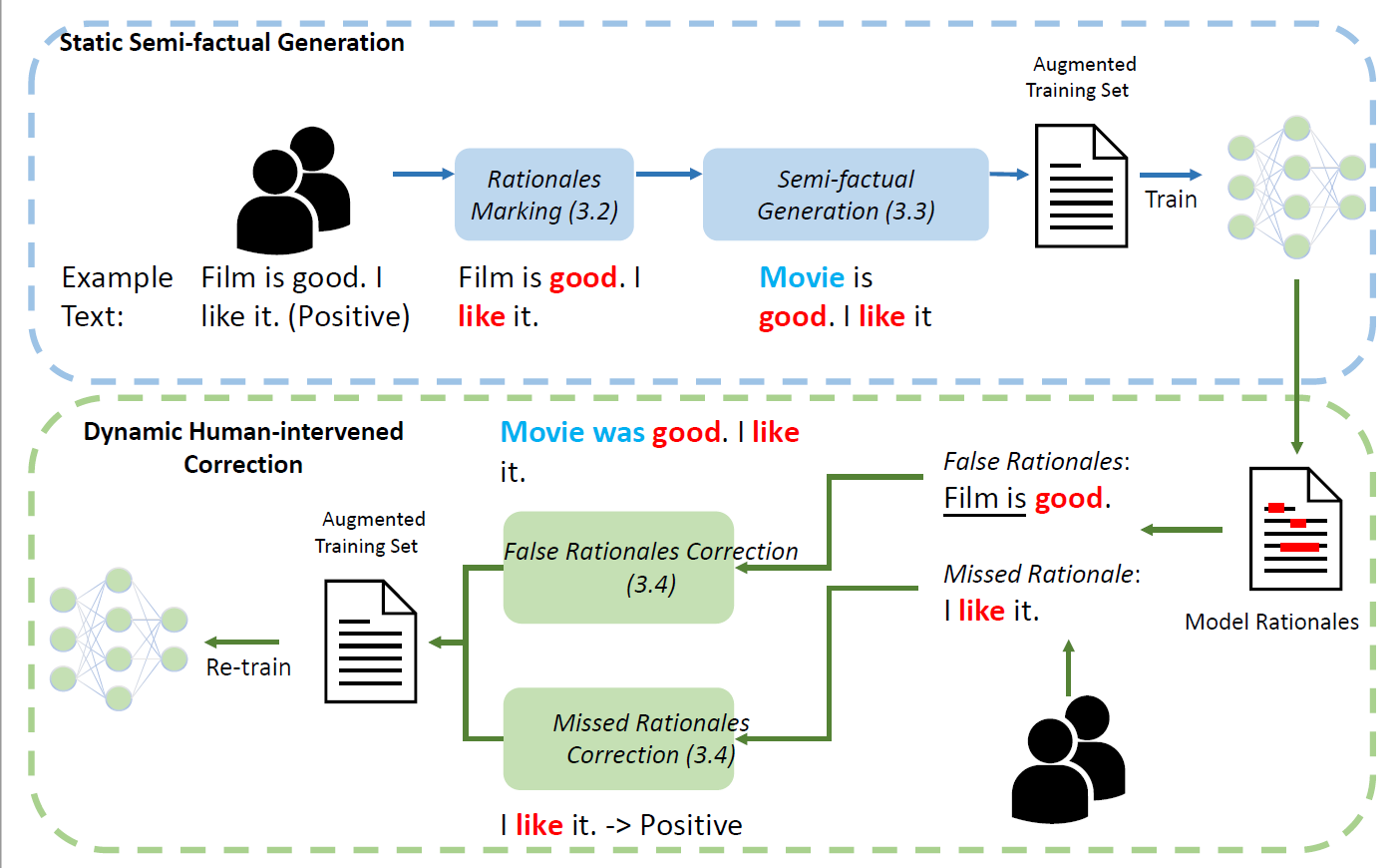
We present a novel rationale-centric framework with human-in-the-loop -- Rationales-centric Double-robustness Learning (RDL) -- to boost model out-of-distribution performance in few-shot learning scenarios. By using static semi-factual generation and dynamic human-intervened correction, RDL exploits rationales (i.e. phrases that cause the prediction), human interventions and semi-factual augmentations to decouple spurious associations and bias models towards generally applicable underlying distributions, which enables fast and accurate generalisation. Experimental results show that RDL leads to significant prediction benefits on both in-distribution and out-of-distribution tests compared to many state-of-the-art benchmarks -- especially for few-shot learning scenarios. We also perform extensive ablation studies to support in-depth analyses of each component in our framework.
PDF Abstract ACL 2022 PDF ACL 2022 Abstract

 SST
SST
 IMDb Movie Reviews
IMDb Movie Reviews
