A Simple Loss Function for Improving the Convergence and Accuracy of Visual Question Answering Models
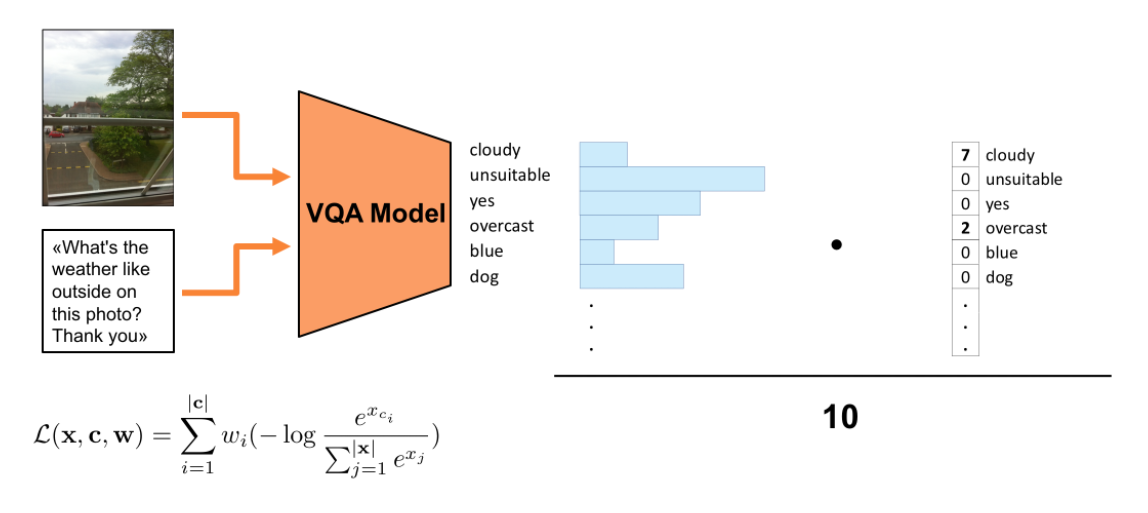
Visual question answering as recently proposed multimodal learning task has enjoyed wide attention from the deep learning community. Lately, the focus was on developing new representation fusion methods and attention mechanisms to achieve superior performance. On the other hand, very little focus has been put on the models' loss function, arguably one of the most important aspects of training deep learning models. The prevailing practice is to use cross entropy loss function that penalizes the probability given to all the answers in the vocabulary except the single most common answer for the particular question. However, the VQA evaluation function compares the predicted answer with all the ground-truth answers for the given question and if there is a matching, a partial point is given. This causes a discrepancy between the model's cross entropy loss and the model's accuracy as calculated by the VQA evaluation function. In this work, we propose a novel loss, termed as soft cross entropy, that considers all ground-truth answers and thus reduces the loss-accuracy discrepancy. The proposed loss leads to an improved training convergence of VQA models and an increase in accuracy as much as 1.6%.
PDF Abstract




