A Survey of Pre-trained Language Models for Processing Scientific Text
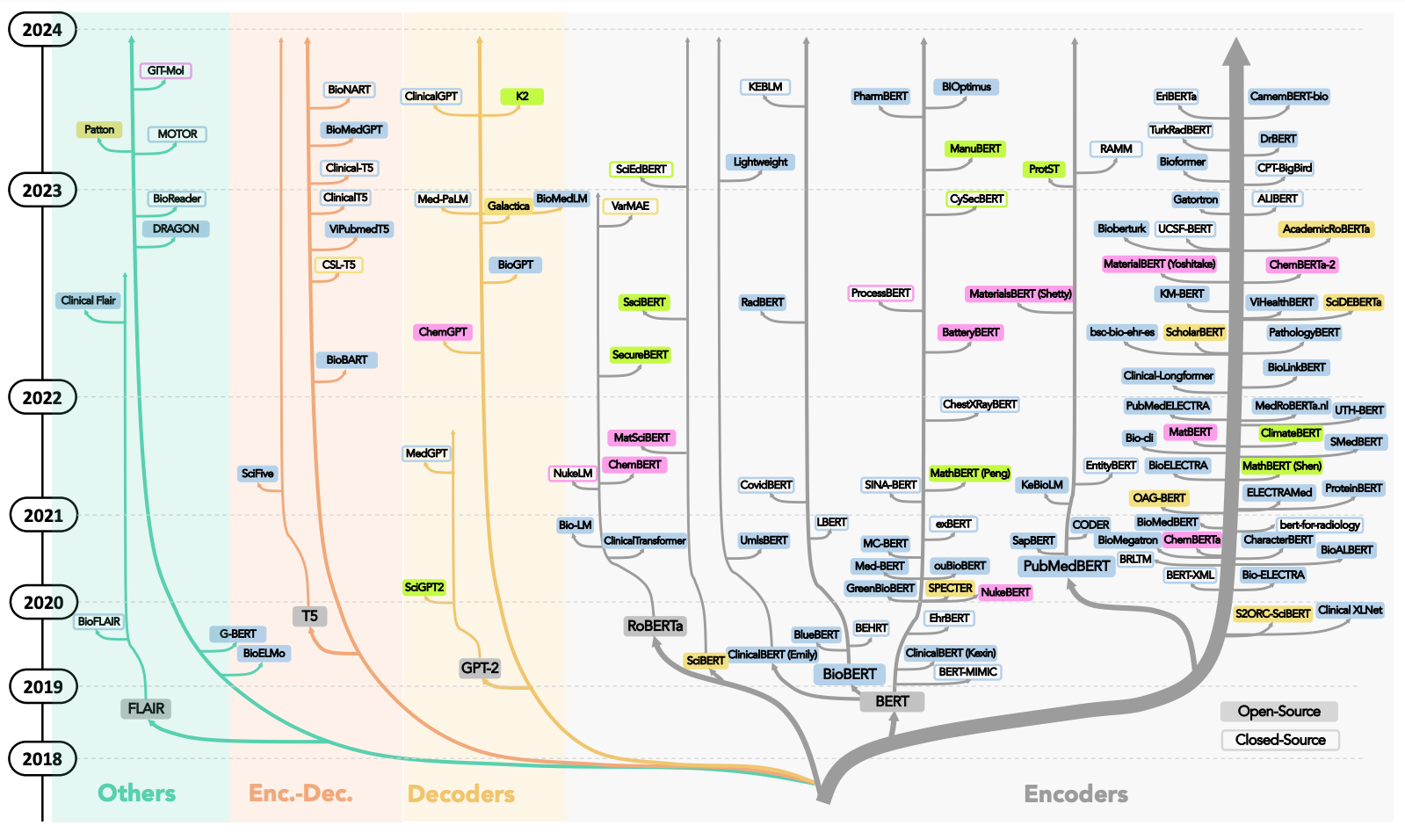
The number of Language Models (LMs) dedicated to processing scientific text is on the rise. Keeping pace with the rapid growth of scientific LMs (SciLMs) has become a daunting task for researchers. To date, no comprehensive surveys on SciLMs have been undertaken, leaving this issue unaddressed. Given the constant stream of new SciLMs, appraising the state-of-the-art and how they compare to each other remain largely unknown. This work fills that gap and provides a comprehensive review of SciLMs, including an extensive analysis of their effectiveness across different domains, tasks and datasets, and a discussion on the challenges that lie ahead.
PDF AbstractCode
Tasks
 GLUE
GLUE
 The Pile
The Pile
 BC5CDR
BC5CDR
 BioASQ
BioASQ
 PubMedQA
PubMedQA
 S2ORC
S2ORC
 BLURB
BLURB
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
