A User-Centric Benchmark for Evaluating Large Language Models
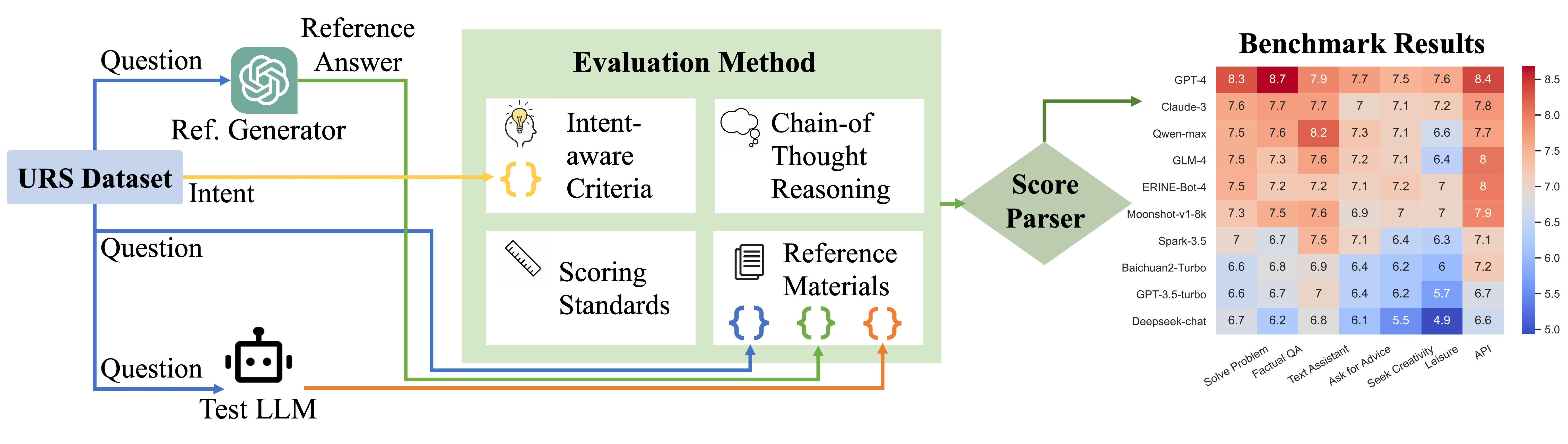
Large Language Models (LLMs) are essential tools to collaborate with users on different tasks. Evaluating their performance to serve users' needs in real-world scenarios is important. While many benchmarks have been created, they mainly focus on specific predefined model abilities. Few have covered the intended utilization of LLMs by real users. To address this oversight, we propose benchmarking LLMs from a user perspective in both dataset construction and evaluation designs. We first collect 1846 real-world use cases with 15 LLMs from a user study with 712 participants from 23 countries. These self-reported cases form the User Reported Scenarios(URS) dataset with a categorization of 7 user intents. Secondly, on this authentic multi-cultural dataset, we benchmark 10 LLM services on their efficacy in satisfying user needs. Thirdly, we show that our benchmark scores align well with user-reported experience in LLM interactions across diverse intents, both of which emphasize the overlook of subjective scenarios. In conclusion, our study proposes to benchmark LLMs from a user-centric perspective, aiming to facilitate evaluations that better reflect real user needs. The benchmark dataset and code are available at https://github.com/Alice1998/URS.
PDF Abstract
 MATH
MATH
