Adaptive Sparse ViT: Towards Learnable Adaptive Token Pruning by Fully Exploiting Self-Attention
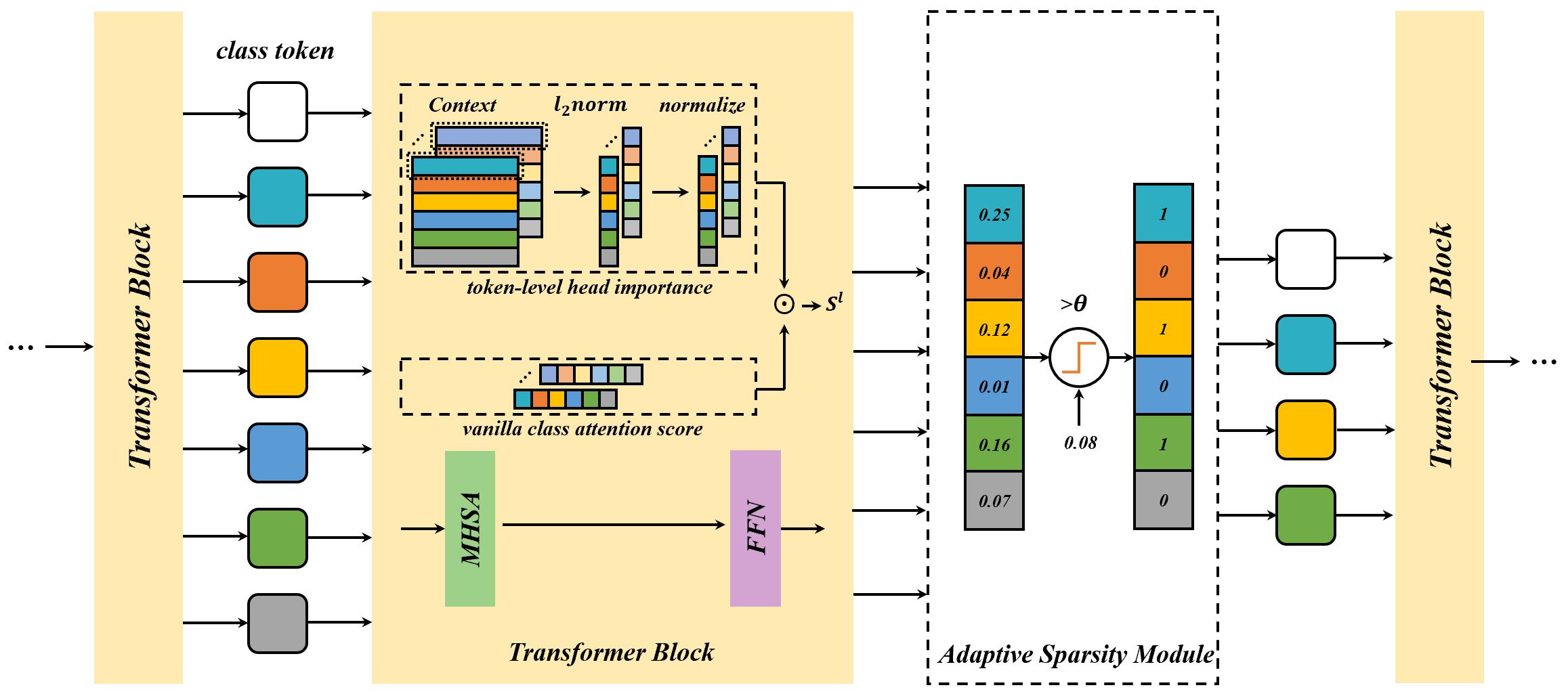
Vision transformer has emerged as a new paradigm in computer vision, showing excellent performance while accompanied by expensive computational cost. Image token pruning is one of the main approaches for ViT compression, due to the facts that the complexity is quadratic with respect to the token number, and many tokens containing only background regions do not truly contribute to the final prediction. Existing works either rely on additional modules to score the importance of individual tokens, or implement a fixed ratio pruning strategy for different input instances. In this work, we propose an adaptive sparse token pruning framework with a minimal cost. Specifically, we firstly propose an inexpensive attention head importance weighted class attention scoring mechanism. Then, learnable parameters are inserted as thresholds to distinguish informative tokens from unimportant ones. By comparing token attention scores and thresholds, we can discard useless tokens hierarchically and thus accelerate inference. The learnable thresholds are optimized in budget-aware training to balance accuracy and complexity, performing the corresponding pruning configurations for different input instances. Extensive experiments demonstrate the effectiveness of our approach. Our method improves the throughput of DeiT-S by 50% and brings only 0.2% drop in top-1 accuracy, which achieves a better trade-off between accuracy and latency than the previous methods.
PDF AbstractCode


Datasets
 ImageNet
ImageNet
Results from the Paper

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Efficient ViTs | ImageNet-1K (with DeiT-S) | AS-DeiT-S (65%) | Top 1 Accuracy | 79.6 | # 16 | |
| GFLOPs | 3.0 | # 23 | ||||
| Efficient ViTs | ImageNet-1K (with DeiT-S) | AS-DeiT-S (50%) | Top 1 Accuracy | 78.7 | # 33 | |
| GFLOPs | 2.3 | # 5 | ||||
| Efficient ViTs | ImageNet-1K (With LV-ViT-S) | AS-LV-S (70%) | Top 1 Accuracy | 83.1 | # 6 | |
| GFLOPs | 4.6 | # 8 | ||||
| Efficient ViTs | ImageNet-1K (With LV-ViT-S) | AS-LV-S (60%) | Top 1 Accuracy | 82.6 | # 13 | |
| GFLOPs | 3.9 | # 14 |
