Align before Attend: Aligning Visual and Textual Features for Multimodal Hateful Content Detection
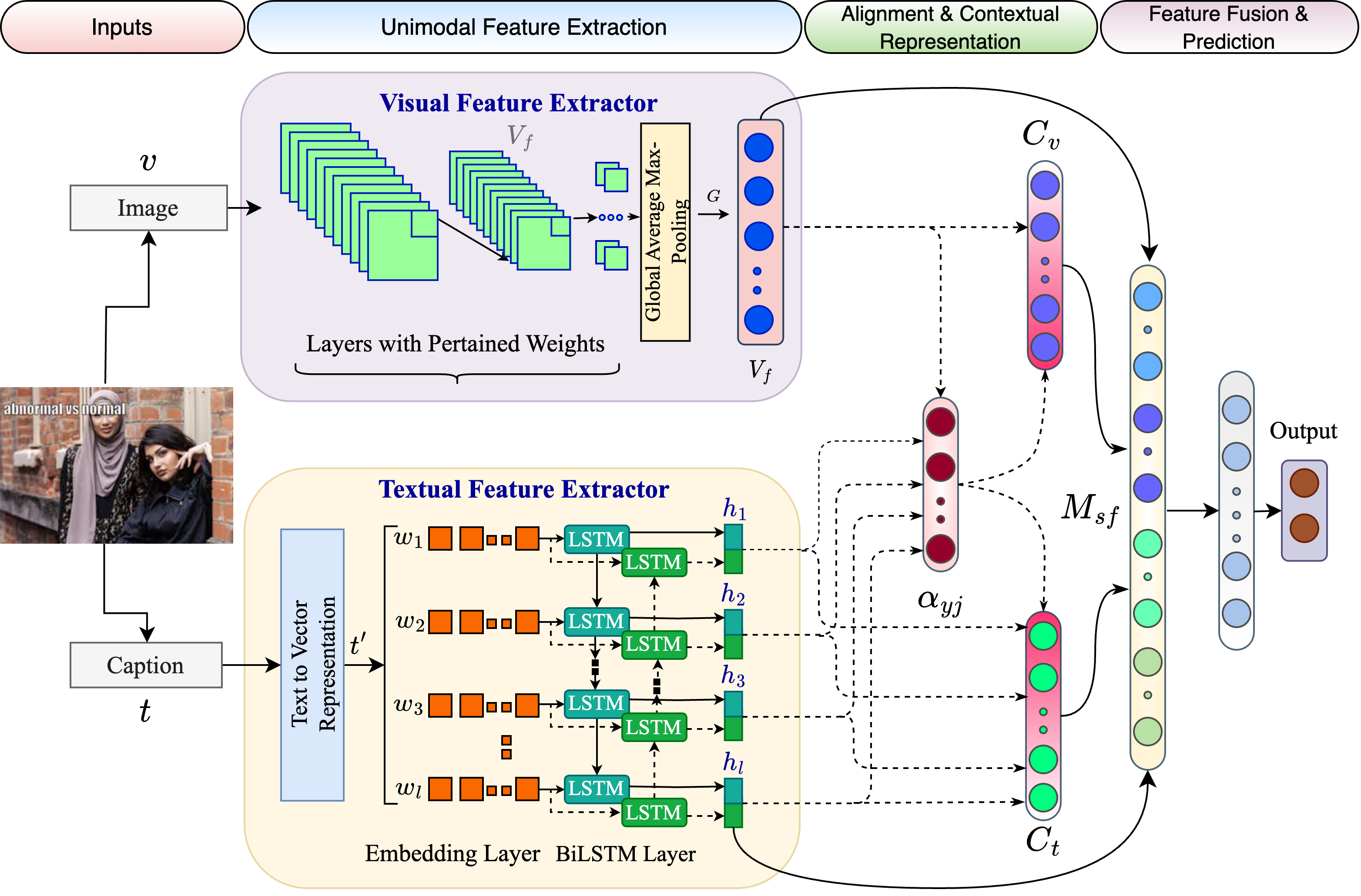
Multimodal hateful content detection is a challenging task that requires complex reasoning across visual and textual modalities. Therefore, creating a meaningful multimodal representation that effectively captures the interplay between visual and textual features through intermediate fusion is critical. Conventional fusion techniques are unable to attend to the modality-specific features effectively. Moreover, most studies exclusively concentrated on English and overlooked other low-resource languages. This paper proposes a context-aware attention framework for multimodal hateful content detection and assesses it for both English and non-English languages. The proposed approach incorporates an attention layer to meaningfully align the visual and textual features. This alignment enables selective focus on modality-specific features before fusing them. We evaluate the proposed approach on two benchmark hateful meme datasets, viz. MUTE (Bengali code-mixed) and MultiOFF (English). Evaluation results demonstrate our proposed approach's effectiveness with F1-scores of $69.7$% and $70.3$% for the MUTE and MultiOFF datasets. The scores show approximately $2.5$% and $3.2$% performance improvement over the state-of-the-art systems on these datasets. Our implementation is available at https://github.com/eftekhar-hossain/Bengali-Hateful-Memes.
PDF Abstract
 Hateful Memes
Hateful Memes
