AlignBench: Benchmarking Chinese Alignment of Large Language Models
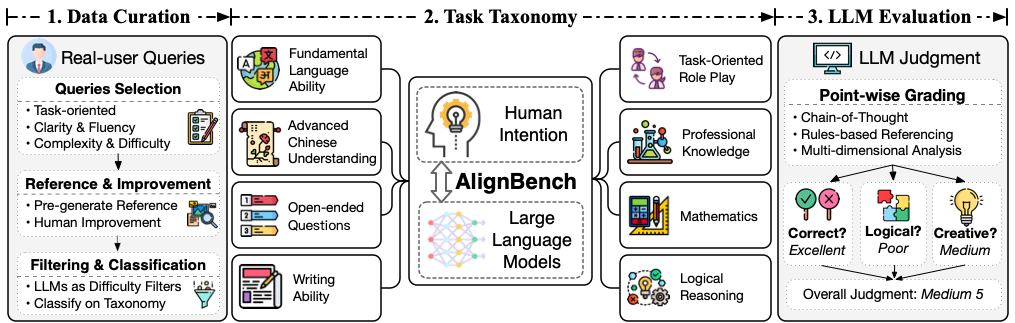
Alignment has become a critical step for instruction-tuned Large Language Models (LLMs) to become helpful assistants. However, effective evaluation of alignment for emerging Chinese LLMs is still significantly lacking, calling for real-scenario grounded, open-ended, challenging and automatic evaluations tailored for alignment. To fill in this gap, we introduce AlignBench, a comprehensive multi-dimensional benchmark for evaluating LLMs' alignment in Chinese. Equipped with a human-in-the-loop data curation pipeline, our benchmark employs a rule-calibrated multi-dimensional LLM-as-Judge with Chain-of-Thought to generate explanations and final ratings as evaluations, ensuring high reliability and interpretability. Furthermore, we report AlignBench evaluated by CritiqueLLM, a dedicated Chinese evaluator LLM that recovers 95% of GPT-4's evaluation ability. We will provide public APIs for evaluating AlignBench with CritiqueLLM to facilitate the evaluation of LLMs' Chinese alignment. All evaluation codes, data, and LLM generations are available at \url{https://github.com/THUDM/AlignBench}.
PDF Abstract
 MMLU
MMLU
