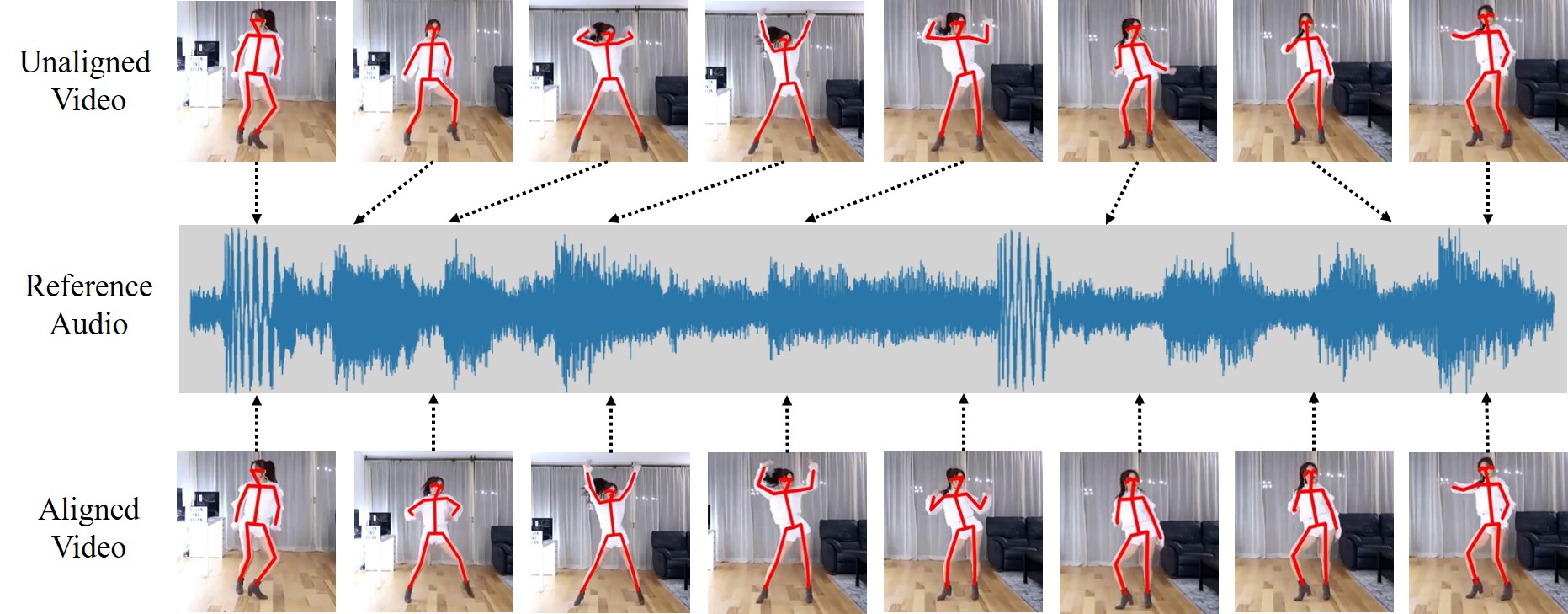
AlignNet: A Unifying Approach to Audio-Visual Alignment
We present AlignNet, a model that synchronizes videos with reference audios under non-uniform and irregular misalignments. AlignNet learns the end-to-end dense correspondence between each frame of a video and an audio. Our method is designed according to simple and well-established principles: attention, pyramidal processing, warping, and affinity function. Together with the model, we release a dancing dataset Dance50 for training and evaluation. Qualitative, quantitative and subjective evaluation results on dance-music alignment and speech-lip alignment demonstrate that our method far outperforms the state-of-the-art methods. Project video and code are available at https://jianrenw.github.io/AlignNet.
PDF AbstractCode

Tasks
 VoxCeleb1
VoxCeleb1
 VoxCeleb2
VoxCeleb2
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
