Scalability vs. Utility: Do We Have to Sacrifice One for the Other in Data Importance Quantification?
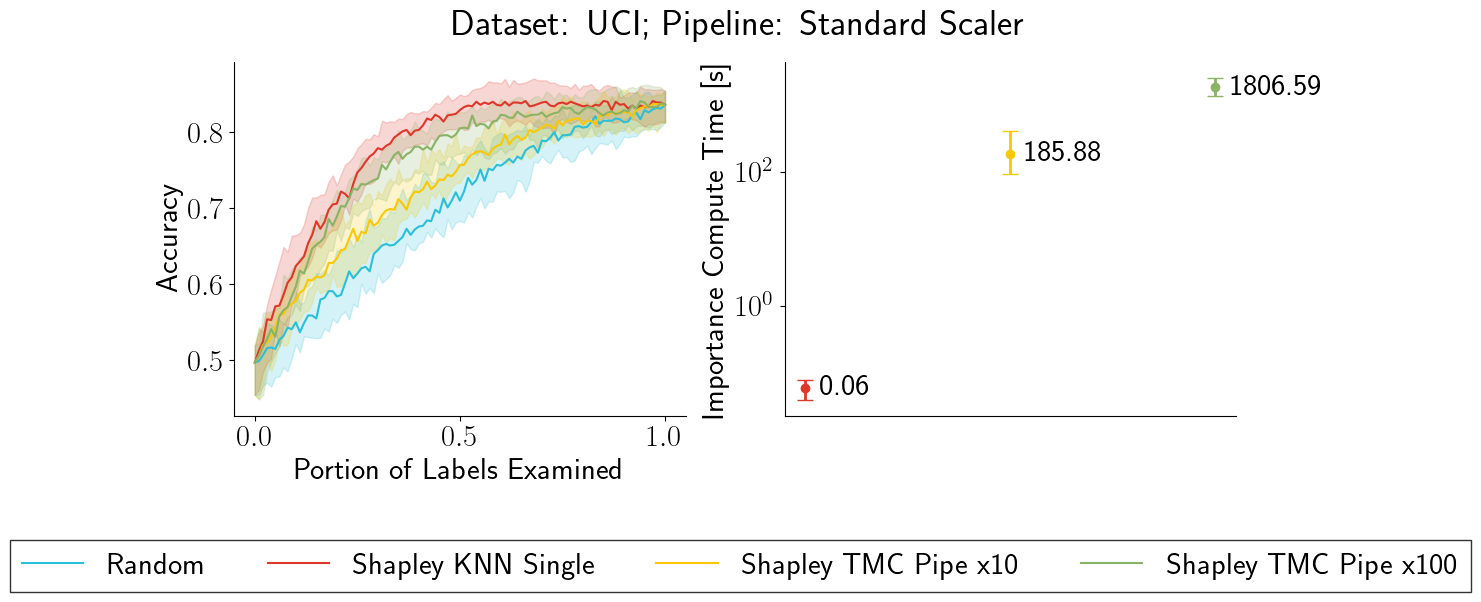
Quantifying the importance of each training point to a learning task is a fundamental problem in machine learning and the estimated importance scores have been leveraged to guide a range of data workflows such as data summarization and domain adaption. One simple idea is to use the leave-one-out error of each training point to indicate its importance. Recent work has also proposed to use the Shapley value, as it defines a unique value distribution scheme that satisfies a set of appealing properties. However, calculating Shapley values is often expensive, which limits its applicability in real-world applications at scale. Multiple heuristics to improve the scalability of calculating Shapley values have been proposed recently, with the potential risk of compromising their utility in real-world applications. \textit{How well do existing data quantification methods perform on existing workflows? How do these methods compare with each other, empirically and theoretically? Must we sacrifice scalability for the utility in these workflows when using these methods?} In this paper, we conduct a novel theoretical analysis comparing the utility of different importance quantification methods, and report extensive experimental studies on existing and proposed workflows such as noisy label detection, watermark removal, data summarization, data acquisition, and domain adaptation. We show that Shapley value approximation based on a $K$NN surrogate over pre-trained feature embeddings obtains comparable utility with existing algorithms while achieving significant scalability improvement, often by orders of magnitude. Our theoretical analysis also justifies its advantage over the leave-one-out error. The code is available at \url{https://github.com/AI-secure/Shapley-Study}.
PDF Abstract CVPR 2021 PDF CVPR 2021 Abstract Colab
Colab



