Analyzing Vision Transformers for Image Classification in Class Embedding Space
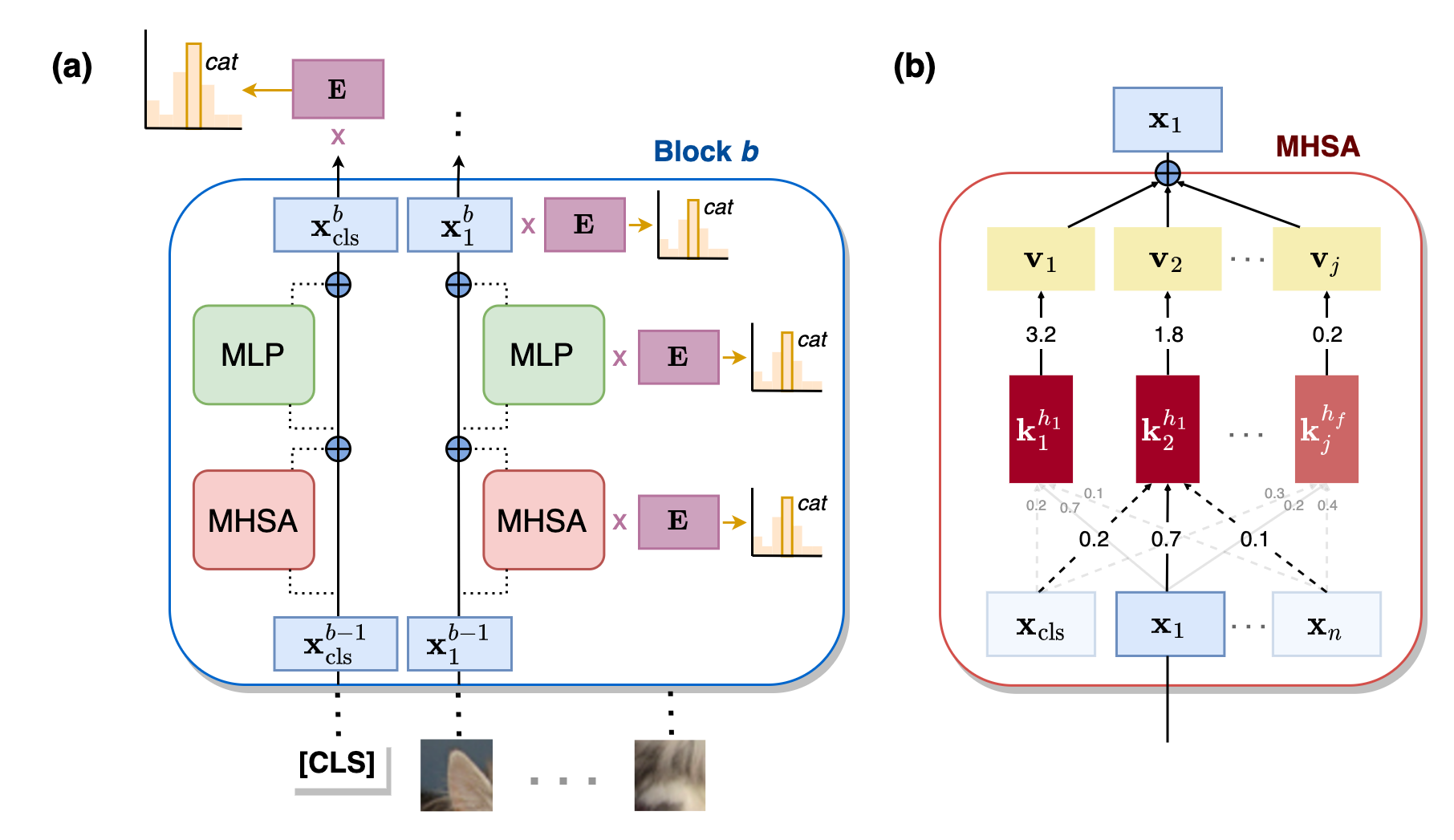
Despite the growing use of transformer models in computer vision, a mechanistic understanding of these networks is still needed. This work introduces a method to reverse-engineer Vision Transformers trained to solve image classification tasks. Inspired by previous research in NLP, we demonstrate how the inner representations at any level of the hierarchy can be projected onto the learned class embedding space to uncover how these networks build categorical representations for their predictions. We use our framework to show how image tokens develop class-specific representations that depend on attention mechanisms and contextual information, and give insights on how self-attention and MLP layers differentially contribute to this categorical composition. We additionally demonstrate that this method (1) can be used to determine the parts of an image that would be important for detecting the class of interest, and (2) exhibits significant advantages over traditional linear probing approaches. Taken together, our results position our proposed framework as a powerful tool for mechanistic interpretability and explainability research.
PDF Abstract NeurIPS 2023 PDF NeurIPS 2023 Abstract Colab
Colab


 CIFAR-100
CIFAR-100
 ImageNet-S
ImageNet-S
