Audio-based Near-Duplicate Video Retrieval with Audio Similarity Learning
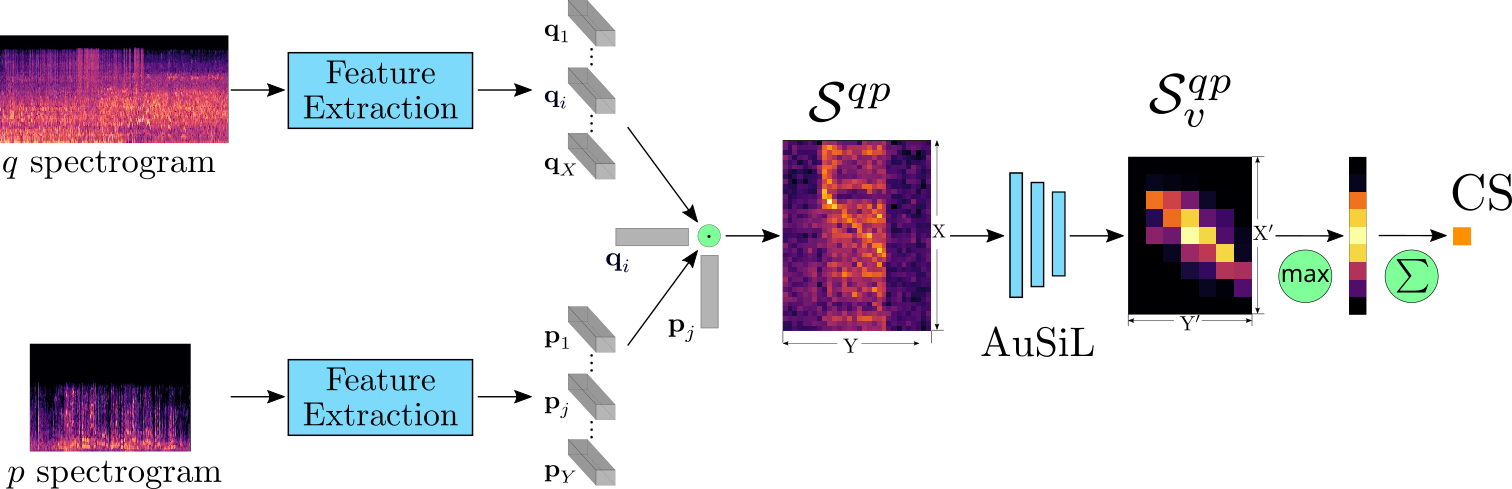
In this work, we address the problem of audio-based near-duplicate video retrieval. We propose the Audio Similarity Learning (AuSiL) approach that effectively captures temporal patterns of audio similarity between video pairs. For the robust similarity calculation between two videos, we first extract representative audio-based video descriptors by leveraging transfer learning based on a Convolutional Neural Network (CNN) trained on a large scale dataset of audio events, and then we calculate the similarity matrix derived from the pairwise similarity of these descriptors. The similarity matrix is subsequently fed to a CNN network that captures the temporal structures existing within its content. We train our network following a triplet generation process and optimizing the triplet loss function. To evaluate the effectiveness of the proposed approach, we have manually annotated two publicly available video datasets based on the audio duplicity between their videos. The proposed approach achieves very competitive results compared to three state-of-the-art methods. Also, unlike the competing methods, it is very robust to the retrieval of audio duplicates generated with speed transformations.
PDF Abstract


 AudioSet
AudioSet
 FIVR-200K
FIVR-200K
