Bag of Tricks for Training Data Extraction from Language Models
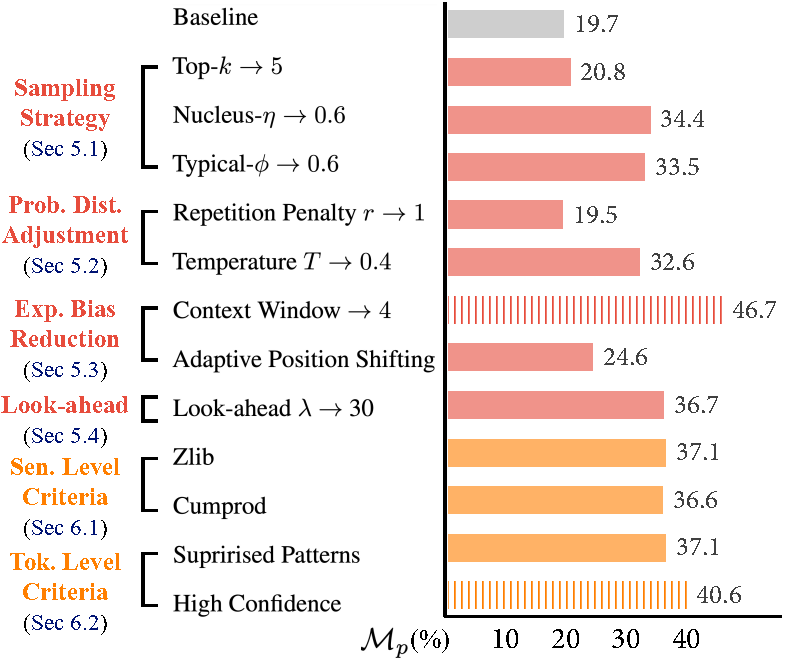
With the advance of language models, privacy protection is receiving more attention. Training data extraction is therefore of great importance, as it can serve as a potential tool to assess privacy leakage. However, due to the difficulty of this task, most of the existing methods are proof-of-concept and still not effective enough. In this paper, we investigate and benchmark tricks for improving training data extraction using a publicly available dataset. Because most existing extraction methods use a pipeline of generating-then-ranking, i.e., generating text candidates as potential training data and then ranking them based on specific criteria, our research focuses on the tricks for both text generation (e.g., sampling strategy) and text ranking (e.g., token-level criteria). The experimental results show that several previously overlooked tricks can be crucial to the success of training data extraction. Based on the GPT-Neo 1.3B evaluation results, our proposed tricks outperform the baseline by a large margin in most cases, providing a much stronger baseline for future research. The code is available at https://github.com/weichen-yu/LM-Extraction.
PDF Abstract

