BASPRO: a balanced script producer for speech corpus collection based on the genetic algorithm
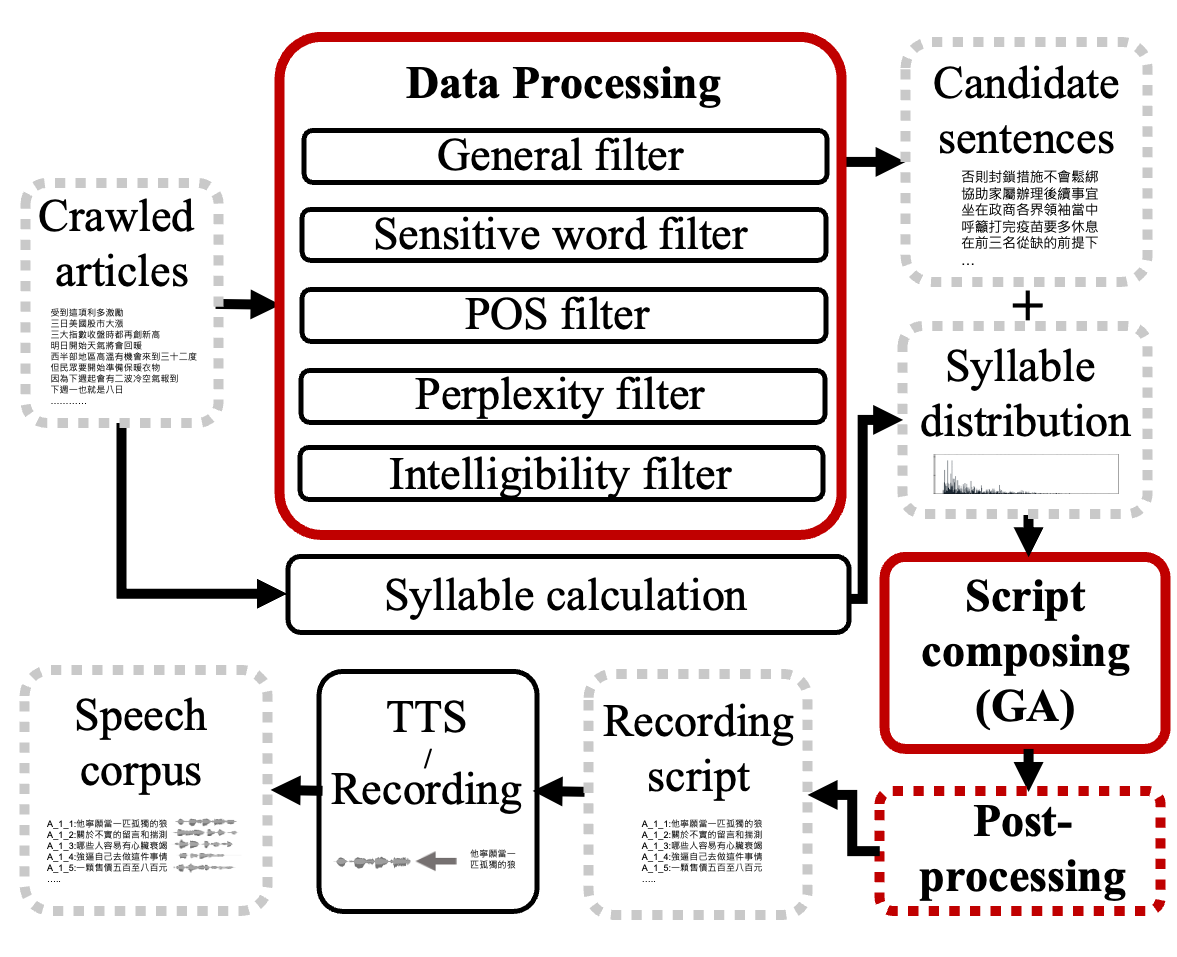
The performance of speech-processing models is heavily influenced by the speech corpus that is used for training and evaluation. In this study, we propose BAlanced Script PROducer (BASPRO) system, which can automatically construct a phonetically balanced and rich set of Chinese sentences for collecting Mandarin Chinese speech data. First, we used pretrained natural language processing systems to extract ten-character candidate sentences from a large corpus of Chinese news texts. Then, we applied a genetic algorithm-based method to select 20 phonetically balanced sentence sets, each containing 20 sentences, from the candidate sentences. Using BASPRO, we obtained a recording script called TMNews, which contains 400 ten-character sentences. TMNews covers 84% of the syllables used in the real world. Moreover, the syllable distribution has 0.96 cosine similarity to the real-world syllable distribution. We converted the script into a speech corpus using two text-to-speech systems. Using the designed speech corpus, we tested the performances of speech enhancement (SE) and automatic speech recognition (ASR), which are one of the most important regression- and classification-based speech processing tasks, respectively. The experimental results show that the SE and ASR models trained on the designed speech corpus outperform their counterparts trained on a randomly composed speech corpus.
PDF Abstract



