Benchmarking the Combinatorial Generalizability of Complex Query Answering on Knowledge Graphs
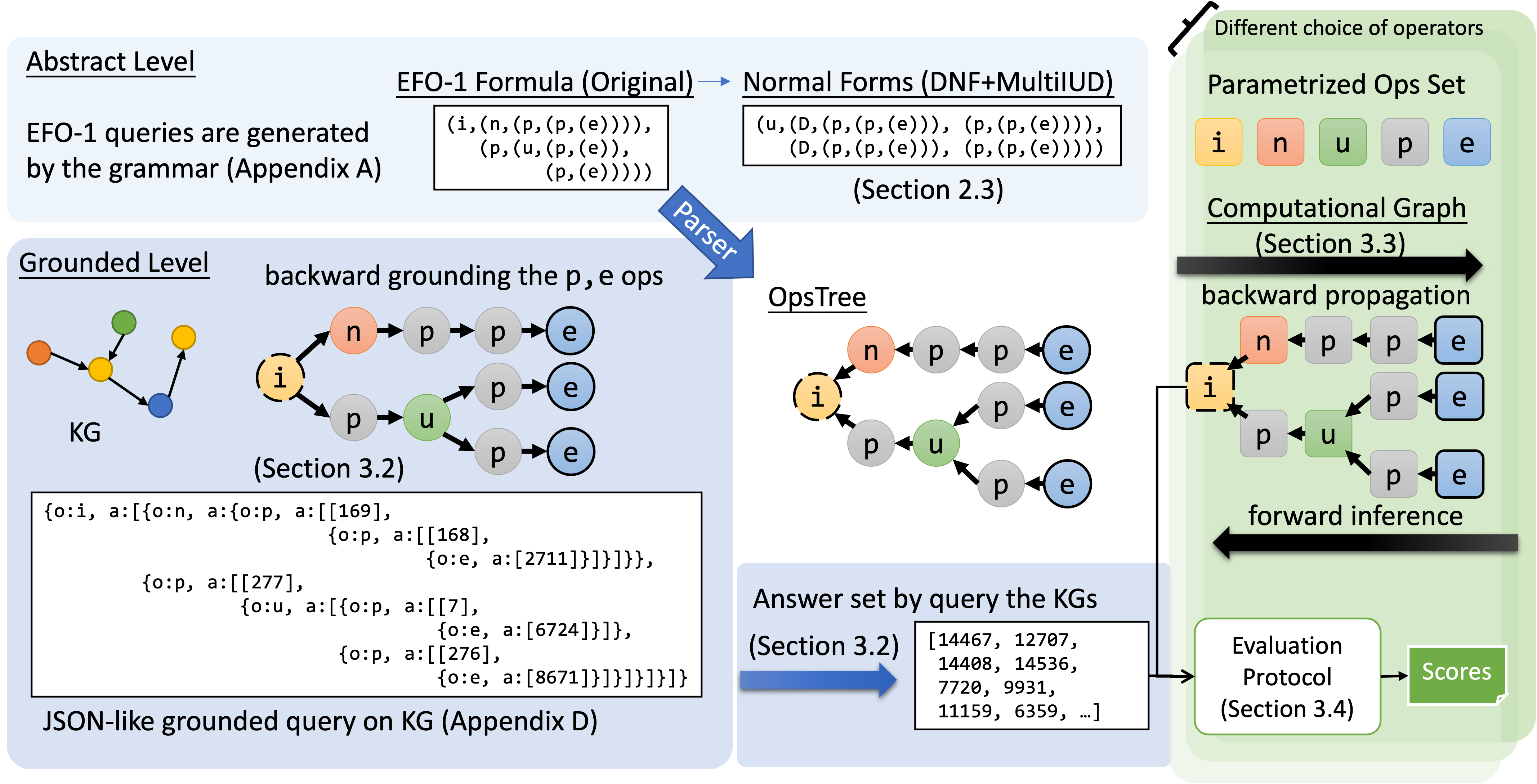
Complex Query Answering (CQA) is an important reasoning task on knowledge graphs. Current CQA learning models have been shown to be able to generalize from atomic operators to more complex formulas, which can be regarded as the combinatorial generalizability. In this paper, we present EFO-1-QA, a new dataset to benchmark the combinatorial generalizability of CQA models by including 301 different queries types, which is 20 times larger than existing datasets. Besides, our work, for the first time, provides a benchmark to evaluate and analyze the impact of different operators and normal forms by using (a) 7 choices of the operator systems and (b) 9 forms of complex queries. Specifically, we provide the detailed study of the combinatorial generalizability of two commonly used operators, i.e., projection and intersection, and justify the impact of the forms of queries given the canonical choice of operators. Our code and data can provide an effective pipeline to benchmark CQA models.
PDF Abstract

 EFO-1-QA
EFO-1-QA
 FB15k
FB15k
 NELL
NELL
