Bidirectional deep-readout echo state networks
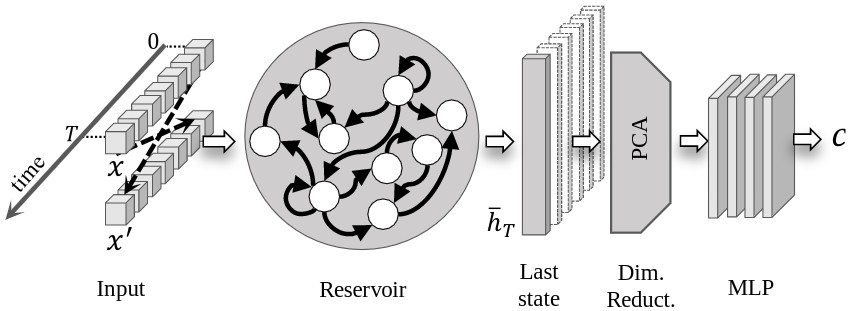
We propose a deep architecture for the classification of multivariate time series. By means of a recurrent and untrained reservoir we generate a vectorial representation that embeds temporal relationships in the data. To improve the memorization capability, we implement a bidirectional reservoir, whose last state captures also past dependencies in the input. We apply dimensionality reduction to the final reservoir states to obtain compressed fixed size representations of the time series. These are subsequently fed into a deep feedforward network trained to perform the final classification. We test our architecture on benchmark datasets and on a real-world use-case of blood samples classification. Results show that our method performs better than a standard echo state network and, at the same time, achieves results comparable to a fully-trained recurrent network, but with a faster training.
PDF Abstract





