BookSum: A Collection of Datasets for Long-form Narrative Summarization
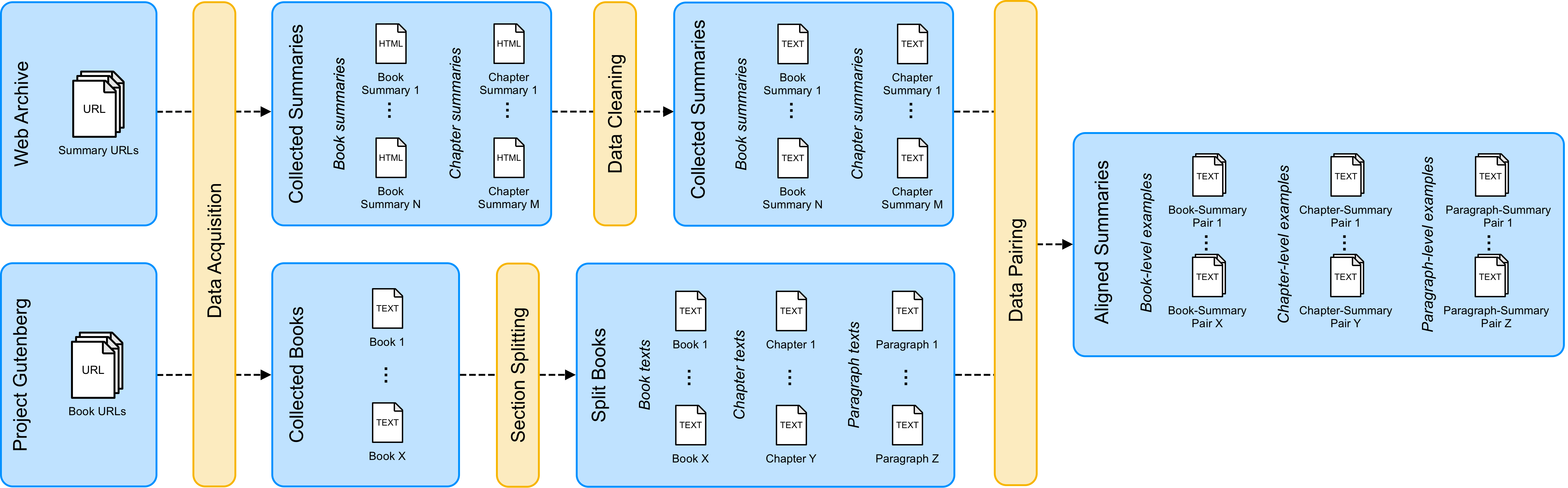
The majority of available text summarization datasets include short-form source documents that lack long-range causal and temporal dependencies, and often contain strong layout and stylistic biases. While relevant, such datasets will offer limited challenges for future generations of text summarization systems. We address these issues by introducing BookSum, a collection of datasets for long-form narrative summarization. Our dataset covers source documents from the literature domain, such as novels, plays and stories, and includes highly abstractive, human written summaries on three levels of granularity of increasing difficulty: paragraph-, chapter-, and book-level. The domain and structure of our dataset poses a unique set of challenges for summarization systems, which include: processing very long documents, non-trivial causal and temporal dependencies, and rich discourse structures. To facilitate future work, we trained and evaluated multiple extractive and abstractive summarization models as baselines for our dataset.
PDF Abstract

 BookSum
BookSum
 NEWSROOM
NEWSROOM
