
Boosting Audio-visual Zero-shot Learning with Large Language Models
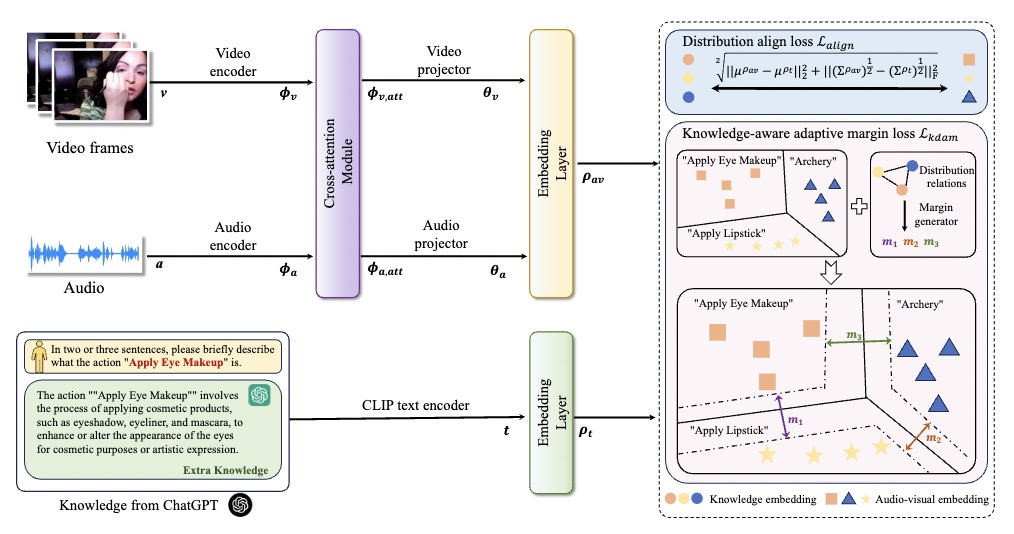
Audio-visual zero-shot learning aims to recognize unseen classes based on paired audio-visual sequences. Recent methods mainly focus on learning multi-modal features aligned with class names to enhance the generalization ability to unseen categories. However, these approaches ignore the obscure event concepts in class names and may inevitably introduce complex network structures with difficult training objectives. In this paper, we introduce a straightforward yet efficient framework called KnowleDge-Augmented audio-visual learning (KDA), which aids the model in more effectively learning novel event content by leveraging an external knowledge base. Specifically, we first propose to utilize the knowledge contained in large language models (LLMs) to generate numerous descriptive sentences that include important distinguishing audio-visual features of event classes, which helps to better understand unseen categories. Furthermore, we propose a knowledge-aware adaptive margin loss to help distinguish similar events, further improving the generalization ability towards unseen classes. Extensive experimental results demonstrate that our proposed KDA can outperform state-of-the-art methods on three popular audio-visual zero-shot learning datasets.Our code will be avaliable at \url{https://github.com/chenhaoxing/KDA}.
PDF Abstract


 ActivityNet
ActivityNet
 VGG-Sound
VGG-Sound

