Cam4DOcc: Benchmark for Camera-Only 4D Occupancy Forecasting in Autonomous Driving Applications
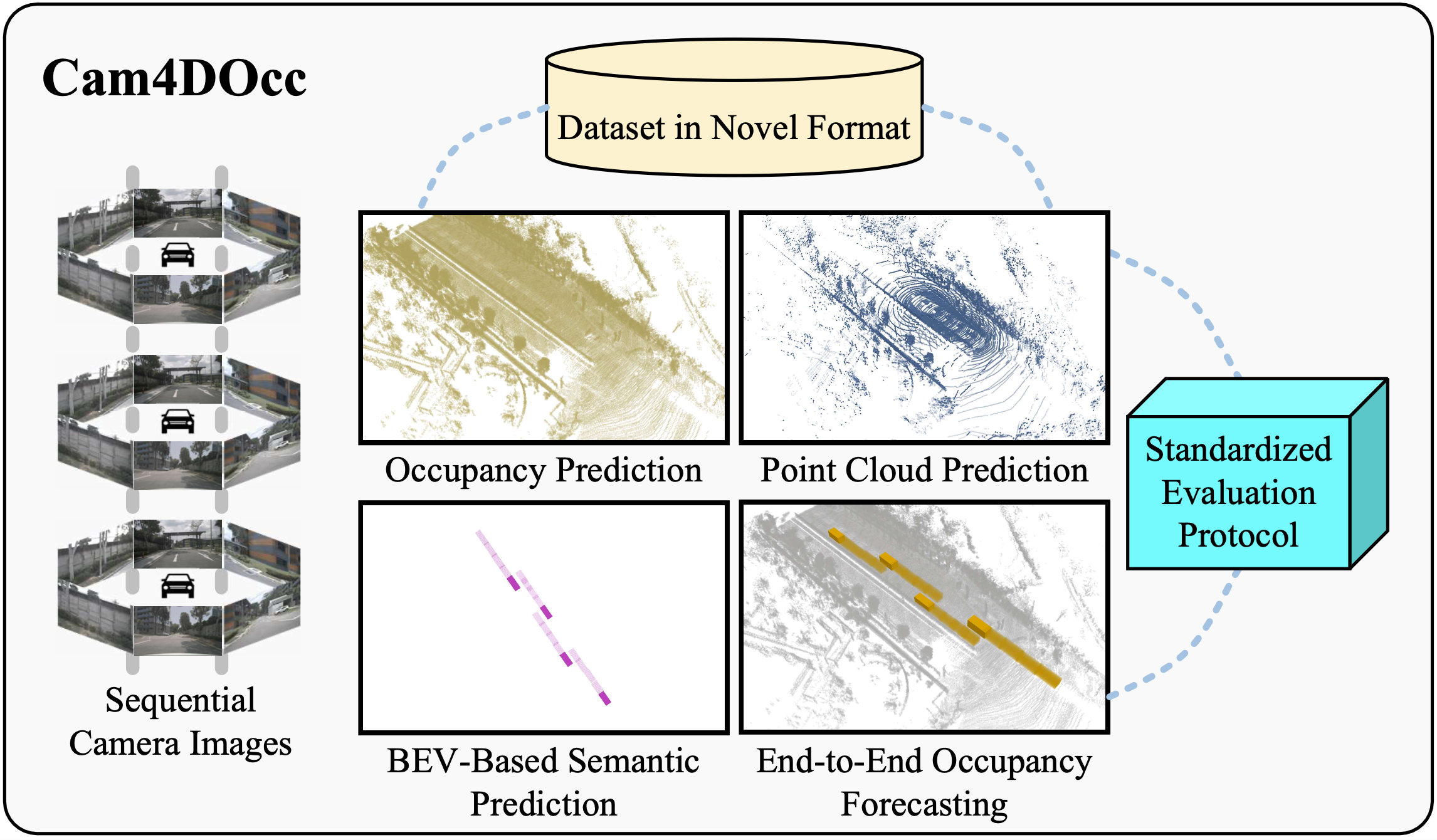
Understanding how the surrounding environment changes is crucial for performing downstream tasks safely and reliably in autonomous driving applications. Recent occupancy estimation techniques using only camera images as input can provide dense occupancy representations of large-scale scenes based on the current observation. However, they are mostly limited to representing the current 3D space and do not consider the future state of surrounding objects along the time axis. To extend camera-only occupancy estimation into spatiotemporal prediction, we propose Cam4DOcc, a new benchmark for camera-only 4D occupancy forecasting, evaluating the surrounding scene changes in a near future. We build our benchmark based on multiple publicly available datasets, including nuScenes, nuScenes-Occupancy, and Lyft-Level5, which provides sequential occupancy states of general movable and static objects, as well as their 3D backward centripetal flow. To establish this benchmark for future research with comprehensive comparisons, we introduce four baseline types from diverse camera-based perception and prediction implementations, including a static-world occupancy model, voxelization of point cloud prediction, 2D-3D instance-based prediction, and our proposed novel end-to-end 4D occupancy forecasting network. Furthermore, the standardized evaluation protocol for preset multiple tasks is also provided to compare the performance of all the proposed baselines on present and future occupancy estimation with respect to objects of interest in autonomous driving scenarios. The dataset and our implementation of all four baselines in the proposed Cam4DOcc benchmark will be released here: https://github.com/haomo-ai/Cam4DOcc.
PDF Abstract

 nuScenes
nuScenes
