Can I Trust Your Answer? Visually Grounded Video Question Answering
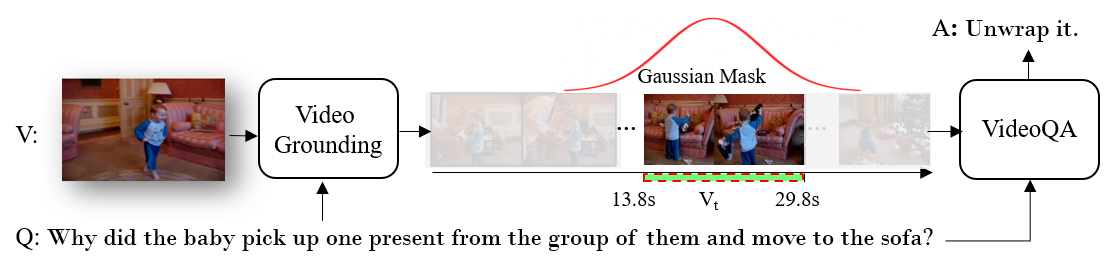
We study visually grounded VideoQA in response to the emerging trends of utilizing pretraining techniques for video-language understanding. Specifically, by forcing vision-language models (VLMs) to answer questions and simultaneously provide visual evidence, we seek to ascertain the extent to which the predictions of such techniques are genuinely anchored in relevant video content, versus spurious correlations from language or irrelevant visual context. Towards this, we construct NExT-GQA -- an extension of NExT-QA with 10.5$K$ temporal grounding (or location) labels tied to the original QA pairs. With NExT-GQA, we scrutinize a series of state-of-the-art VLMs. Through post-hoc attention analysis, we find that these models are extremely weak in substantiating the answers despite their strong QA performance. This exposes the limitation of current VLMs in making reliable predictions. As a remedy, we further explore and propose a grounded-QA method via Gaussian mask optimization and cross-modal learning. Experiments with different backbones demonstrate that this grounding mechanism improves both grounding and QA. With these efforts, we aim to push towards trustworthy VLMs in VQA systems. Our dataset and code are available at https://github.com/doc-doc/NExT-GQA.
PDF Abstract



 NExT-GQA
NExT-GQA
 TVQA
TVQA
 NExT-QA
NExT-QA
 TVQA+
TVQA+
 VidSTG
VidSTG
