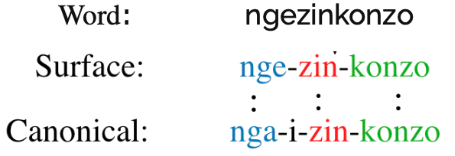
Canonical and Surface Morphological Segmentation for Nguni Languages
Morphological Segmentation involves decomposing words into morphemes, the smallest meaning-bearing units of language. This is an important NLP task for morphologically-rich agglutinative languages such as the Southern African Nguni language group. In this paper, we investigate supervised and unsupervised models for two variants of morphological segmentation: canonical and surface segmentation. We train sequence-to-sequence models for canonical segmentation, where the underlying morphemes may not be equal to the surface form of the word, and Conditional Random Fields (CRF) for surface segmentation. Transformers outperform LSTMs with attention on canonical segmentation, obtaining an average F1 score of 72.5% across 4 languages. Feature-based CRFs outperform bidirectional LSTM-CRFs to obtain an average of 97.1% F1 on surface segmentation. In the unsupervised setting, an entropy-based approach using a character-level LSTM language model fails to outperforms a Morfessor baseline, while on some of the languages neither approach performs much better than a random baseline. We hope that the high performance of the supervised segmentation models will help to facilitate the development of better NLP tools for Nguni languages.
PDF Abstract


