CompiLIG at SemEval-2017 Task 1: Cross-Language Plagiarism Detection Methods for Semantic Textual Similarity
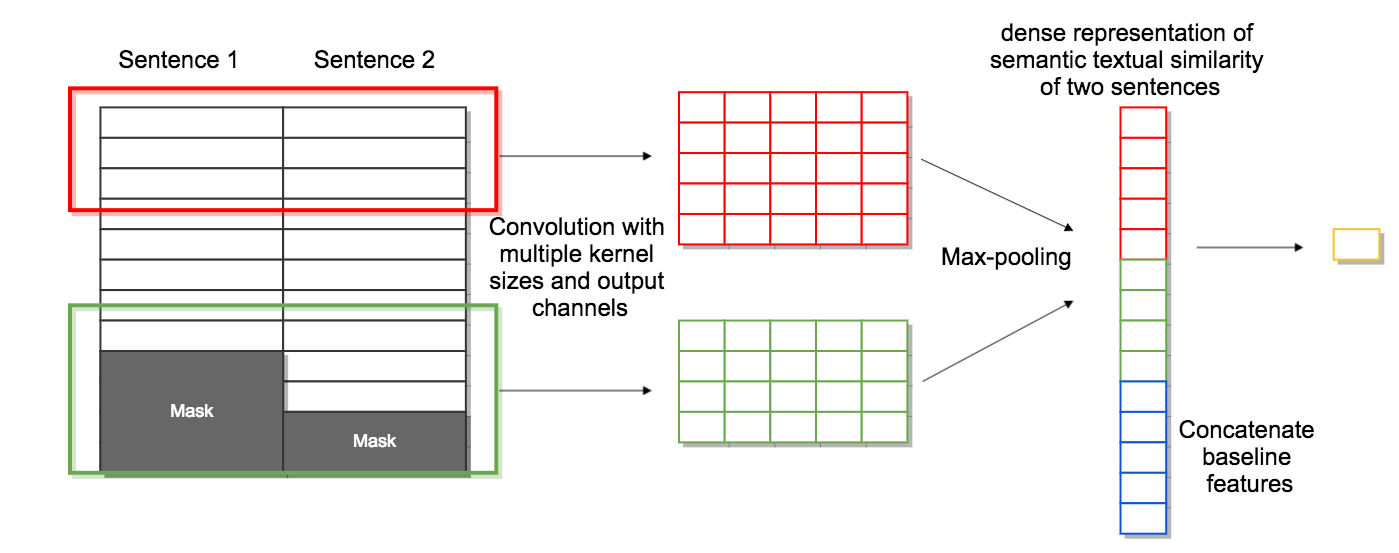
We present our submitted systems for Semantic Textual Similarity (STS) Track 4 at SemEval-2017. Given a pair of Spanish-English sentences, each system must estimate their semantic similarity by a score between 0 and 5. In our submission, we use syntax-based, dictionary-based, context-based, and MT-based methods. We also combine these methods in unsupervised and supervised way. Our best run ranked 1st on track 4a with a correlation of 83.02% with human annotations.
PDF Abstract SEMEVAL 2017 PDF SEMEVAL 2017 Abstract


Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
