Compression-aware Continual Learning using Singular Value Decomposition
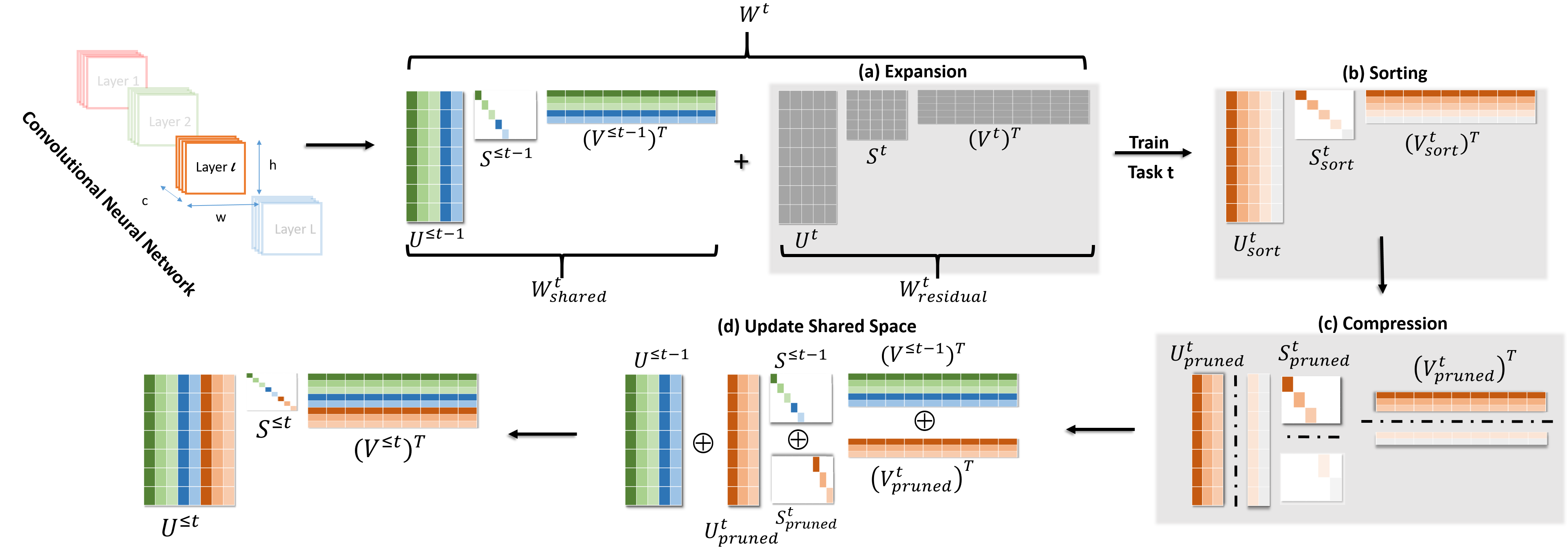
We propose a compression based continual task learning method that can dynamically grow a neural network. Inspired from the recent model compression techniques, we employ compression-aware training and perform low-rank weight approximations using singular value decomposition (SVD) to achieve network compaction. By encouraging the network to learn low-rank weight filters, our method achieves compressed representations with minimal performance degradation without the need for costly fine-tuning. Specifically, we decompose the weight filters using SVD and train the network on incremental tasks in its factorized form. Such a factorization allows us to directly impose sparsity-inducing regularizers over the singular values and allows us to use fewer number of parameters for each task. We further introduce a novel shared representational space based learning between tasks. This promotes the incoming tasks to only learn residual task-specific information on top of the previously learnt weight filters and greatly helps in learning under fixed capacity constraints. Our method significantly outperforms prior continual learning approaches on three benchmark datasets, demonstrating accuracy improvements of 10.3%, 12.3%, 15.6% on 20-split CIFAR-100, miniImageNet and a 5-sequence dataset, respectively, over state-of-the-art. Further, our method yields compressed models that have ~3.64x, 2.88x, 5.91x fewer number of parameters respectively, on the above mentioned datasets in comparison to baseline individual task models. Our source code is available at https://github.com/pavanteja295/CACL.
PDF Abstract


 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
