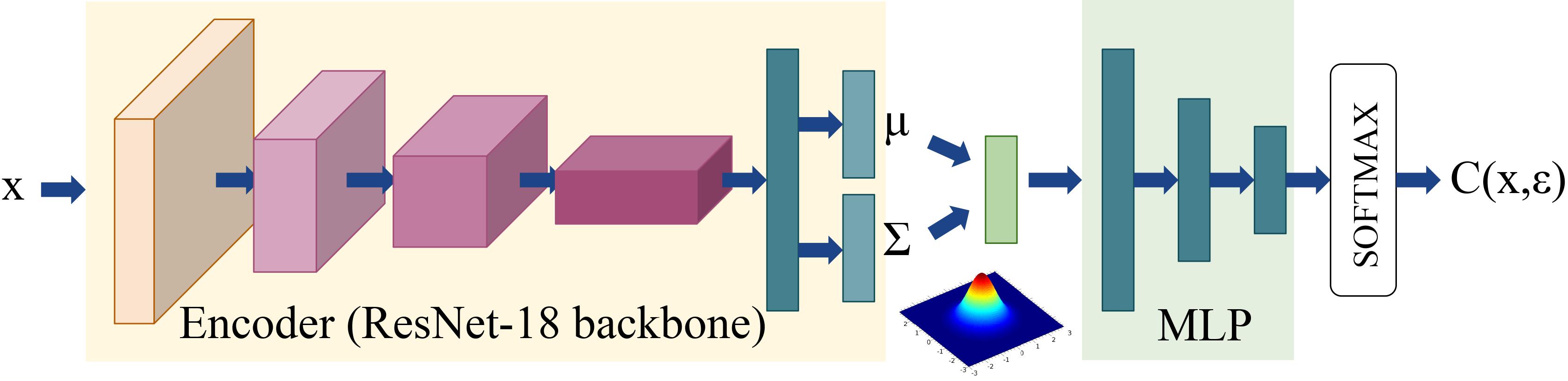
Confidence-Calibrated Adversarial Training: Generalizing to Unseen Attacks
Adversarial training yields robust models against a specific threat model, e.g., $L_\infty$ adversarial examples. Typically robustness does not generalize to previously unseen threat models, e.g., other $L_p$ norms, or larger perturbations. Our confidence-calibrated adversarial training (CCAT) tackles this problem by biasing the model towards low confidence predictions on adversarial examples. By allowing to reject examples with low confidence, robustness generalizes beyond the threat model employed during training. CCAT, trained only on $L_\infty$ adversarial examples, increases robustness against larger $L_\infty$, $L_2$, $L_1$ and $L_0$ attacks, adversarial frames, distal adversarial examples and corrupted examples and yields better clean accuracy compared to adversarial training. For thorough evaluation we developed novel white- and black-box attacks directly attacking CCAT by maximizing confidence. For each threat model, we use $7$ attacks with up to $50$ restarts and $5000$ iterations and report worst-case robust test error, extended to our confidence-thresholded setting, across all attacks.
PDF Abstract ICML 2020 PDF
 CIFAR-10
CIFAR-10
 SVHN
SVHN
