Contrastive Spatio-Temporal Pretext Learning for Self-supervised Video Representation
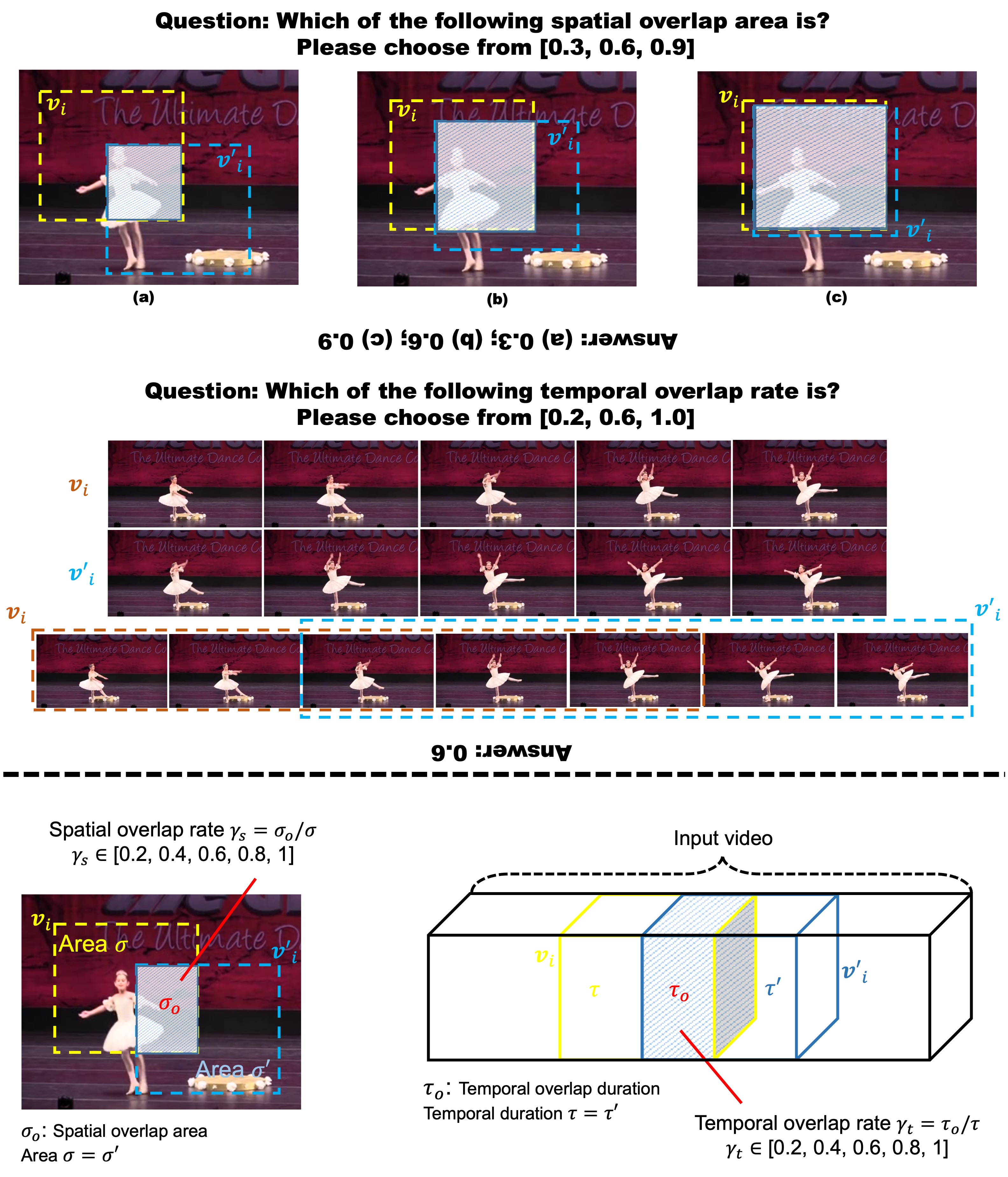
Spatio-temporal representation learning is critical for video self-supervised representation. Recent approaches mainly use contrastive learning and pretext tasks. However, these approaches learn representation by discriminating sampled instances via feature similarity in the latent space while ignoring the intermediate state of the learned representations, which limits the overall performance. In this work, taking into account the degree of similarity of sampled instances as the intermediate state, we propose a novel pretext task - spatio-temporal overlap rate (STOR) prediction. It stems from the observation that humans are capable of discriminating the overlap rates of videos in space and time. This task encourages the model to discriminate the STOR of two generated samples to learn the representations. Moreover, we employ a joint optimization combining pretext tasks with contrastive learning to further enhance the spatio-temporal representation learning. We also study the mutual influence of each component in the proposed scheme. Extensive experiments demonstrate that our proposed STOR task can favor both contrastive learning and pretext tasks. The joint optimization scheme can significantly improve the spatio-temporal representation in video understanding. The code is available at https://github.com/Katou2/CSTP.
PDF Abstract



 UCF101
UCF101
 HMDB51
HMDB51
