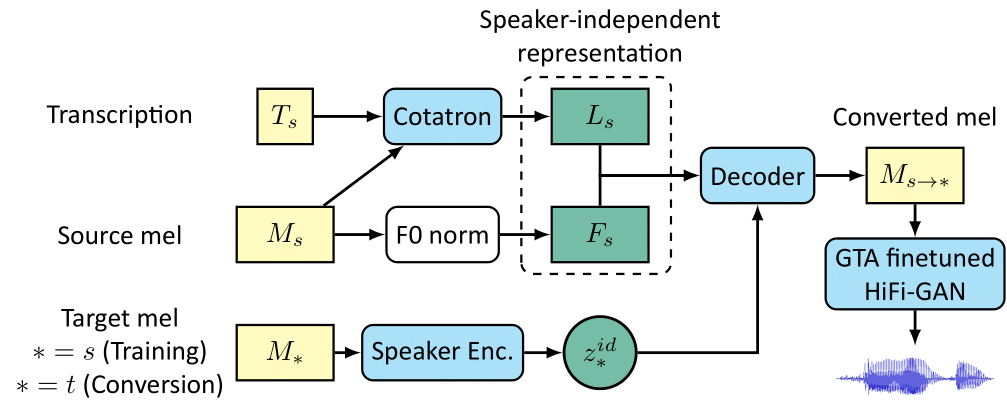
Controllable and Interpretable Singing Voice Decomposition via Assem-VC
We propose a singing decomposition system that encodes time-aligned linguistic content, pitch, and source speaker identity via Assem-VC. With decomposed speaker-independent information and the target speaker's embedding, we could synthesize the singing voice of the target speaker. In conclusion, we made a perfectly synced duet with the user's singing voice and the target singer's converted singing voice.
PDF AbstractCode
 Colab
Colab

Tasks

Datasets
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
