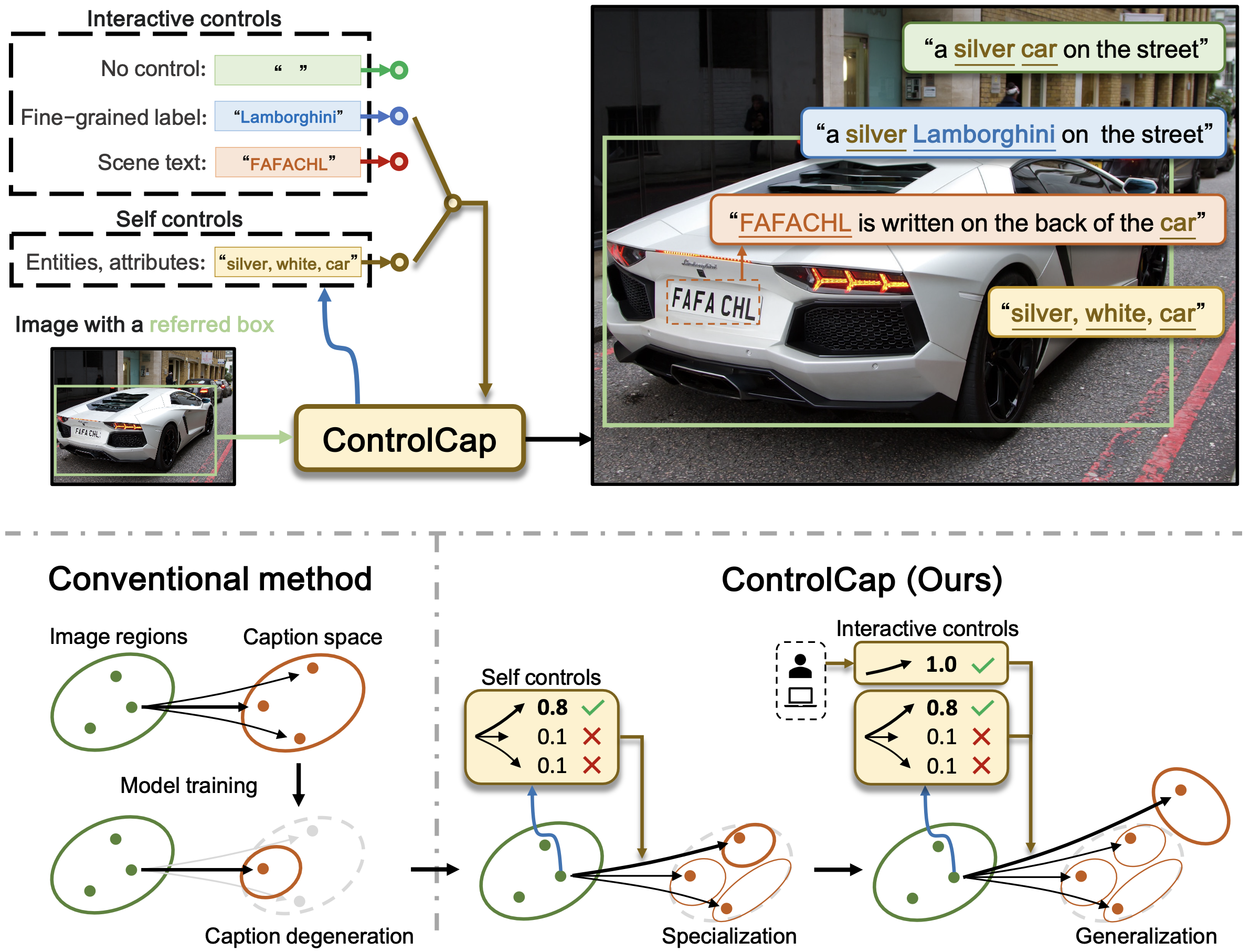
ControlCap: Controllable Region-level Captioning
Region-level captioning is challenged by the caption degeneration issue, which refers to that pre-trained multimodal models tend to predict the most frequent captions but miss the less frequent ones. In this study, we propose a controllable region-level captioning (ControlCap) approach, which introduces control words to a multimodal model to address the caption degeneration issue. In specific, ControlCap leverages a discriminative module to generate control words within the caption space to partition it to multiple sub-spaces. The multimodal model is constrained to generate captions within a few sub-spaces containing the control words, which increases the opportunity of hitting less frequent captions, alleviating the caption degeneration issue. Furthermore, interactive control words can be given by either a human or an expert model, which enables captioning beyond the training caption space, enhancing the model's generalization ability. Extensive experiments on Visual Genome and RefCOCOg datasets show that ControlCap respectively improves the CIDEr score by 21.6 and 2.2, outperforming the state-of-the-arts by significant margins. Code is available at https://github.com/callsys/ControlCap.
PDF AbstractCode

Tasks

Datasets
 ImageNet
ImageNet
 Visual Genome
Visual Genome

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Dense Captioning | Visual Genome | ControlCap | mAP | 18.2 | # 1 |
