ControlVideo: Conditional Control for One-shot Text-driven Video Editing and Beyond
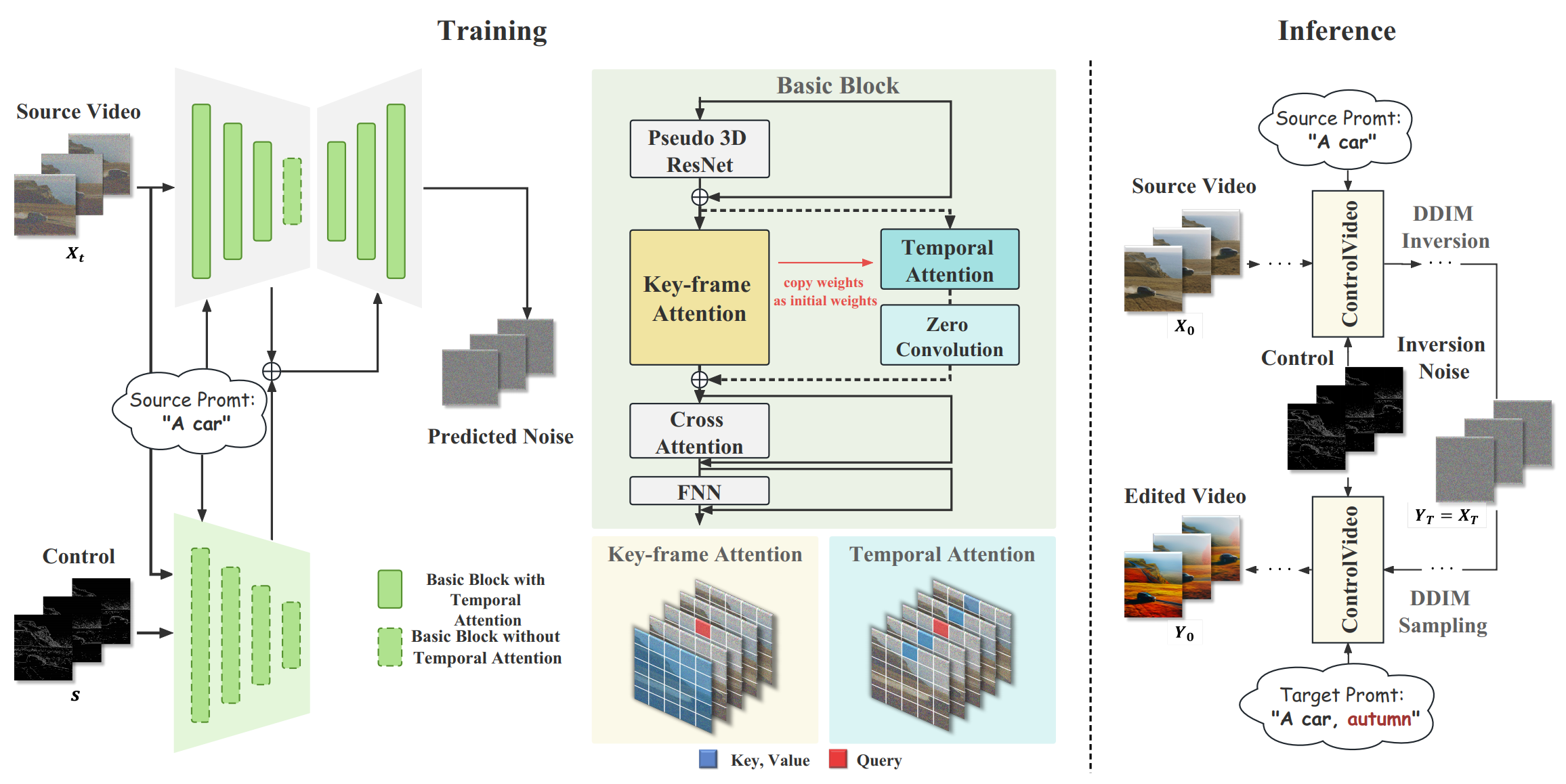
This paper presents \emph{ControlVideo} for text-driven video editing -- generating a video that aligns with a given text while preserving the structure of the source video. Building on a pre-trained text-to-image diffusion model, ControlVideo enhances the fidelity and temporal consistency by incorporating additional conditions (such as edge maps), and fine-tuning the key-frame and temporal attention on the source video-text pair via an in-depth exploration of the design space. Extensive experimental results demonstrate that ControlVideo outperforms various competitive baselines by delivering videos that exhibit high fidelity w.r.t. the source content, and temporal consistency, all while aligning with the text. By incorporating Low-rank adaptation layers into the model before training, ControlVideo is further empowered to generate videos that align seamlessly with reference images. More importantly, ControlVideo can be readily extended to the more challenging task of long video editing (e.g., with hundreds of frames), where maintaining long-range temporal consistency is crucial. To achieve this, we propose to construct a fused ControlVideo by applying basic ControlVideo to overlapping short video segments and key frame videos and then merging them by pre-defined weight functions. Empirical results validate its capability to create videos across 140 frames, which is approximately 5.83 to 17.5 times more than what previous works achieved. The code is available at \href{https://github.com/thu-ml/controlvideo}{https://github.com/thu-ml/controlvideo} and the visualization results are available at \href{https://drive.google.com/file/d/1wEgc2io3UwmoC5vTPbkccFvTkwVqsZlK/view?usp=drive_link}{HERE}.
PDF Abstract

